本文总结了当前在线地图构造任务的相关工作
方向简介
高精地图构建的传统方案需要事先采集点云,使用SLAM方法离线构造全局一致的地图,并在地图上标注语义信息。这样的流程虽然能制作精确的高精地图,但采集、标注和维护都需要大量的人力。近年来,虽然有一些车道线检测的工作是基于车载传感器实现的,但车道线检测只是地图生成的一个子任务,并且相关数据集往往只提供front-view的数据,且只提供线性元素的标注数据,相关的研究工作也非常受限。恰逢BEV和多传感器融合技术的发展,一些工作尝试使用车载传感器进行在线的局部地图学习。
由于传感器输出的数据和目标地图位于不同的坐标系,仅使用车载传感器作为模型输入尤其颇具挑战性。起初也是把在线地图学习作为一个分割任务来学习,主要操作是将地图栅格化为像素,然后给每个像素分配一个类别标签。
但是栅格地图并不是自动驾驶任务最合适的表示形式:
- 栅格地图缺乏instance信息,对于区分具有相同类标签但语义不同的地图元素存在困难(如左边界和右边界)
- 难以在预测的栅格化地图中强制执行空间一致性,例如,邻近的像素的语义或者几何形状可能是冲突的
- 与下游任务不兼容,自动驾驶中后续的预测和规划模块多使用instance级别的2D/3D矢量化地图
近期出现了一些工作使用车载传感器实时生成矢量化的局部语义地图。这种工作并不旨在取代全局高清地图重建,而是提供一种简单的方法来预测局部语义地图,用于实时运动预测和规划。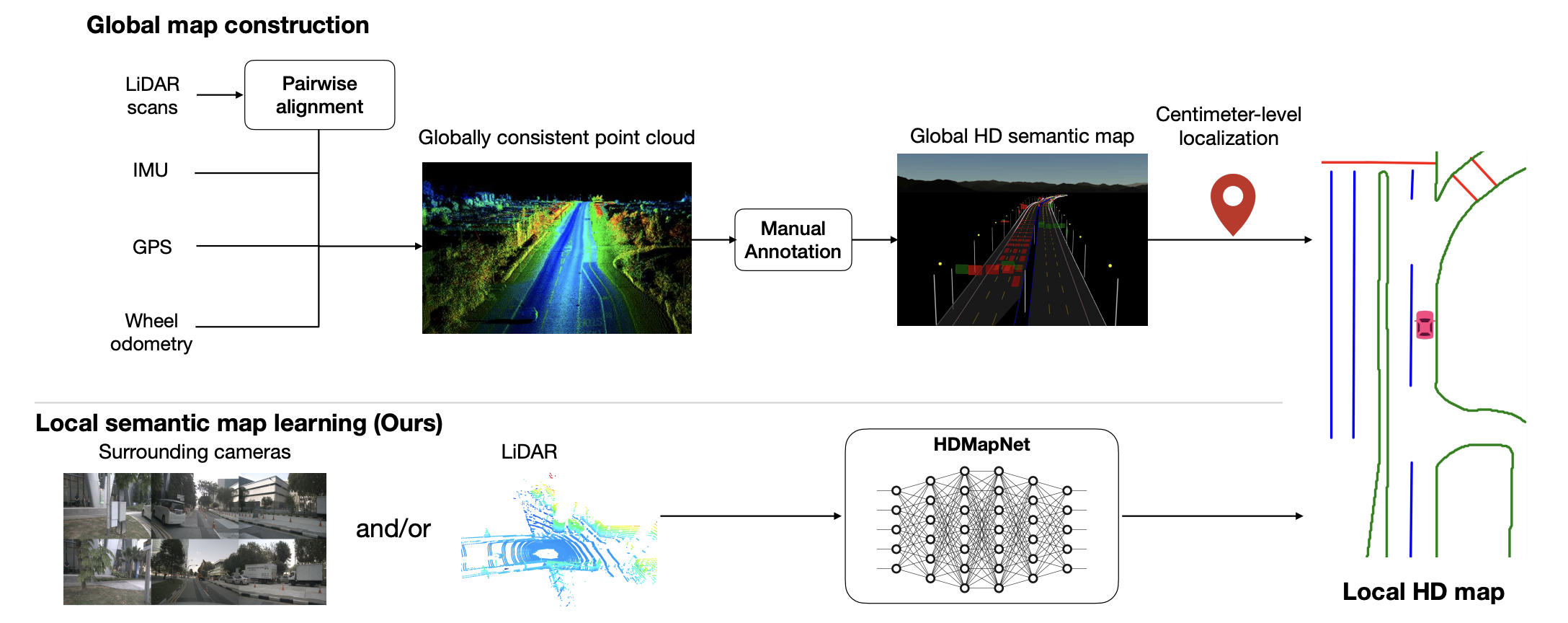
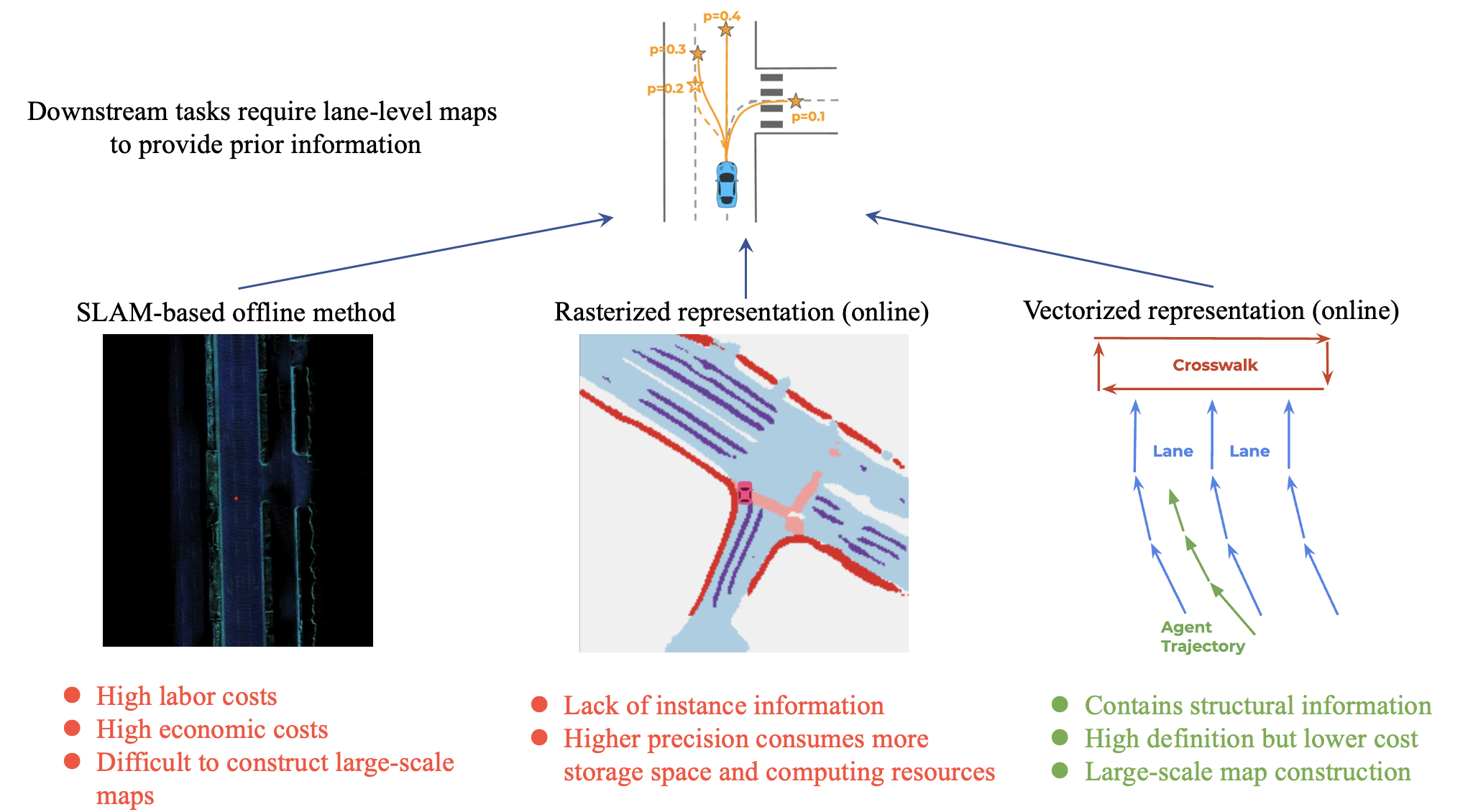
具体来说,使用多段线表示地图元素的优点如下:
- 高精地图通常由不同几何图形混合组成,例如点、线、曲线和多边形。折线是一种灵活的基元,可以有效地表示这些几何元素
- 折线顶点的顺序是编码地图元素方向的自然方式,这对驾驶至关重要
- 折线表示已经广泛应用于下游自动驾驶模块,如运动预测等
因此,地图学习任务也可以归结为从传感器数据中预测一个稀疏的折线集合(set prediction)。本文将对这个领域的相关论文进行具体的介绍。
现有主要论文
[202203] HDMapNet
Title:HDMapNet: An Online HD Map Construction and Evaluation Framework
TL;DR: HDMapNet遵循常规的语义分割pipeline的密集预测方案,在后处理中通过启发式的聚类算法得到矢量化的地图元素。
Motivation: 高精地图生成的传统方案需要大量的人力物力去标注和维护地图的语义信息,限制了其规模。
Result: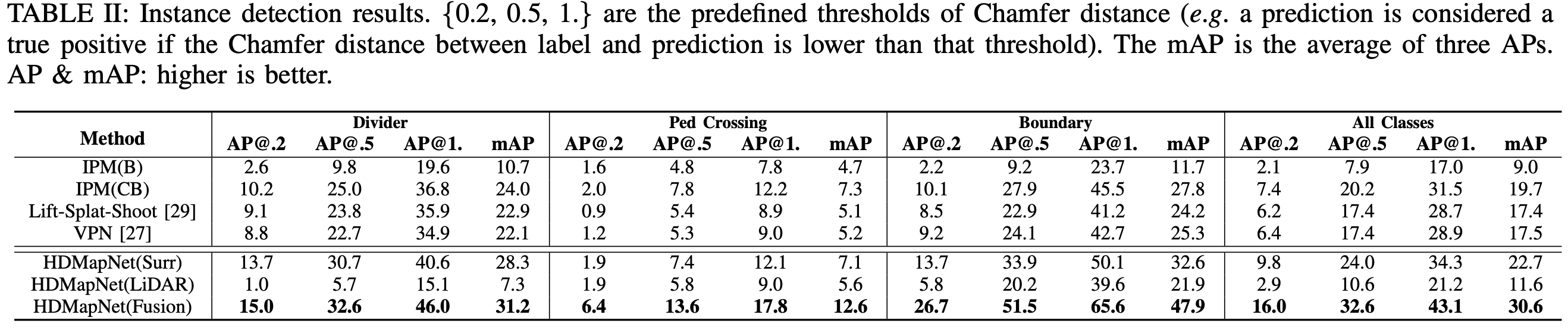
Pipeline
HDMapNet本质上还是将在线地图学习任务看作是一个语义分割任务,这种任务非常适合使用卷积+全连接网络进行求解。模型Pipeline如图4所示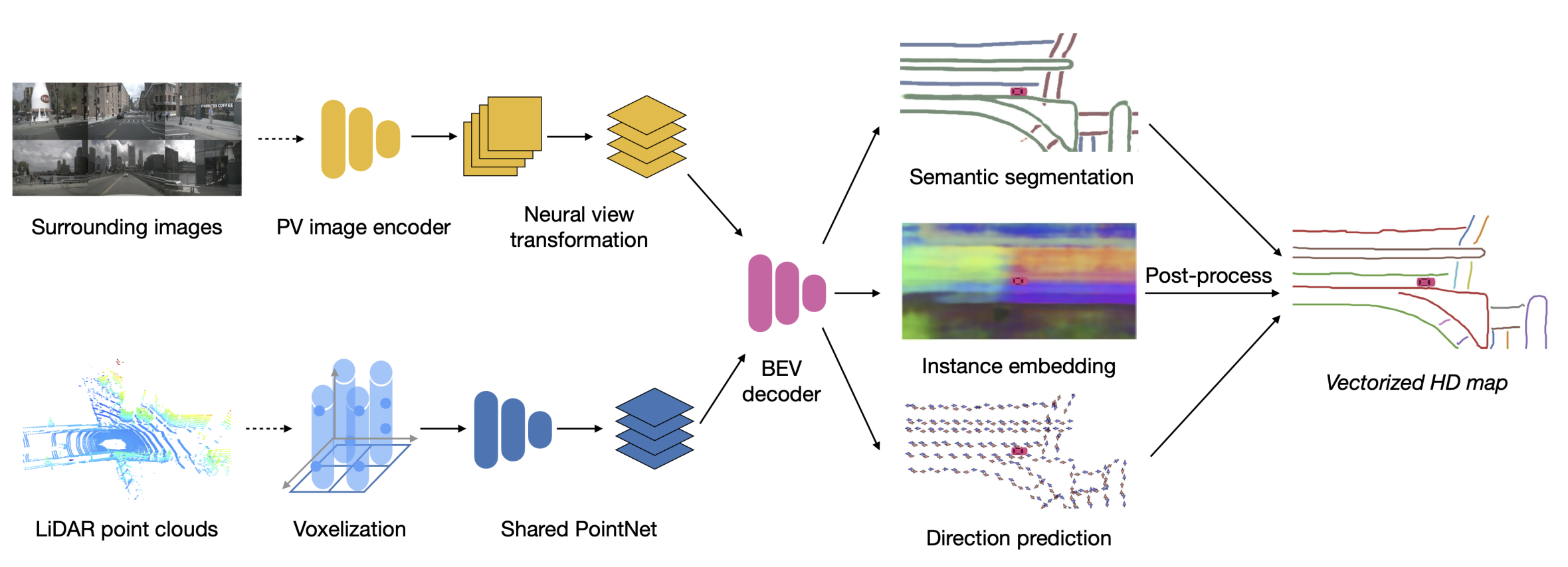
- PV Encoder
在视角转换部分,HDMapNet是使用MLP讲特征从图像坐标系转到相机坐标系,然后使用IPM投影将其转到自车坐标系 - LiDar Encoder
参考的是PointPillar的方案 - BEV Decoder
通过三个卷积block得到语义图、实例图和方向图三个输出。- 语义图是pixel-level的分类结果。
- 实例图是。
- 方向图预测的是pixel-level地图元素的方向。方向共划分了$N_d$个类别。
- 通过手工设计的后处理算法将这三种地图矢量化。
Loss设计
$L_{seg}$是semantic prediction模块中使用的CE loss。
$L_{ins_embedding}$是instance embedding模块中对每个bev embedding进行聚类的损失,$L_{var}$和$L_{dist}$分别是方差和距离的损失,二者都是L2 loss
对于点集中点的匹配关系,使用的是Chamfer distance进行度量
优点
- 率先提出了矢量化的在线高精地图构造思路
缺点
- 实际上还是依赖栅格化的地图预测
- 启发式后处理步骤使整个pipeline变得复杂,也非常耗时,限制了模型的可伸缩性和性能
[202206] VectorMapNet
Title:VectorMapNet: End-to-end Vectorized HD Map Learning
TL;DR:VectorMapNet提出了第一个端到端的矢量地图构造方案,无需任何后处理操作。
Motivation: 现有的在线地图学习方案要么是基于栅格地图预测的,没有instance信息;要么就需要复杂的后处理步骤。
Result: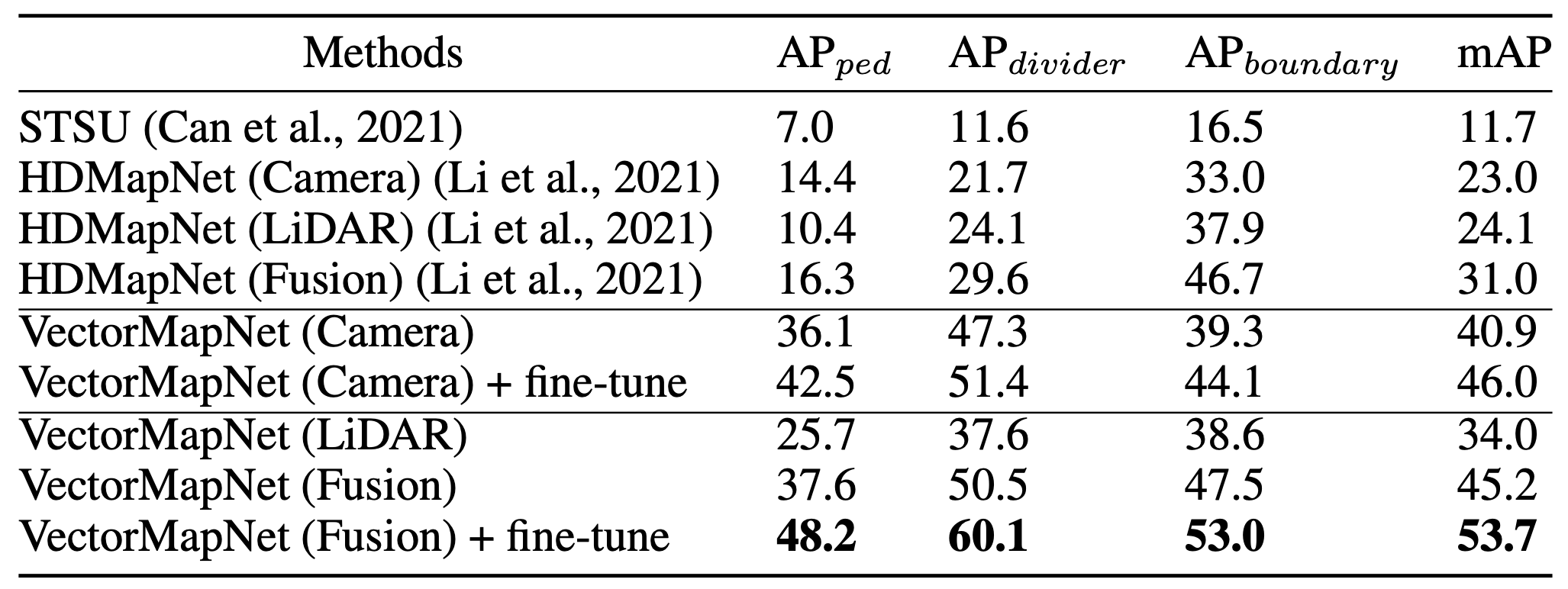
Pipeline
VectorMapNet将在线地图生成任务描述为一个稀疏的集合任务,这种任务非常适合使用Transformer进行求解,这个任务也可以顺理成章地转换成检测任务进行处理。
VectorMapNet是一个两阶段的方案,第一阶段是一个set prediction任务,预测策略的关键点;第二阶段是一个sequence generation任务,按顺序预测地图元素的下一个点。VectorMapNet的pipeline如图6所示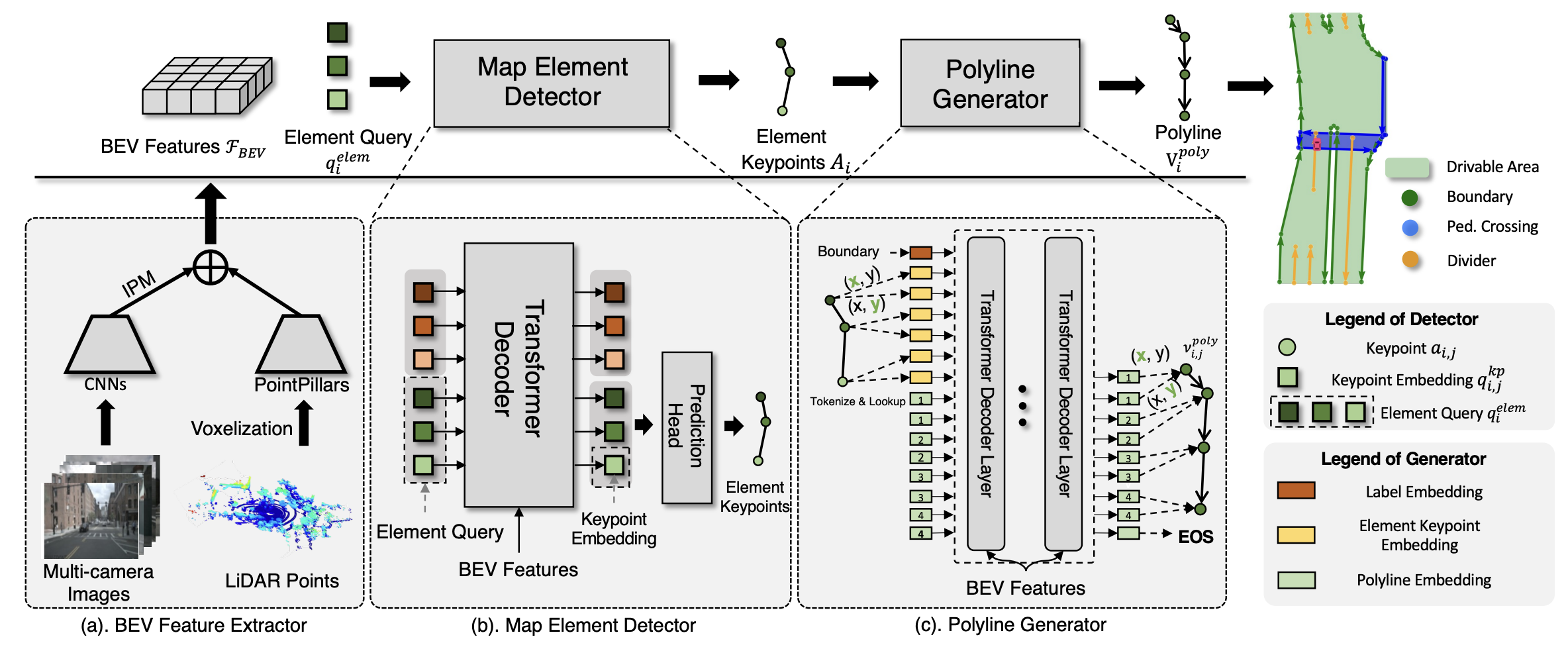
VectorMapNet首先将不同模态的数据整合到BEV特征空间,然后基于可学习的query检测地图元素的位置和类别,最后将每个地图元素解码成polyline。每个模块具体实现的拆解如下
- BEV Feature Extractor
将传感器得到的数据(相机图像)转换到鸟瞰图视角(BEV)中得到BEV features。这里使用的也是IPM的方案。 - Map Element Detector
主要的目的就是定位每一个地图元素的位置,大致形状以及所属类别。这里论文中称其将每一个地图元素用多个关键点(Keypoints)来表示,实际上就是用bounding box封装了一下 - Polyline Generator
这个模块根据检测模块检测到的关键点和类别信息来预测每个地图元素的具体的局部几何形状,将每一个地图元素补充完整。模块推断用公式描述为
loss设计
loss设计包括两个部分,分别是检测损失和生成损失
其中,$\mathcal{L}_{det}$是由两个个部分组成的损失函数,包括关键点回归损失和分类损失,$\mathcal{L}_{gen}$则是交叉熵损失。
由于生成器是一个序列生成模型,采用教师指导(teacher-forcing)训练方法进行训练。
优点
- 无须复杂的后处理过程,能够直接端到端的得到矢量地图元素
- 将地图构造问题转成set prediction的问题,使得基于transformer的方案能够轻松移植过来
缺点
- 基于box的封装方式,一方面不能准确表示元素的形状;另一方面,box对于线性目标会退化(尤其是驾驶场景中元素常与坐标轴平行)
- 有向折线表示地图元素和顺序预测点会引起定义歧义
- 以循环的方式预测点,并采用级联的由粗到细框架,导致较长的推理时间和对实时场景的有限可伸缩性。且自回归解码器的周期性导致了累积误差的问题,需要更长的训练时间才能收敛
[202208]MapTR
Title:MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
TL;DR: MapTR直接建模地图元素的元素-点的关系,采用类似DETR的方式直接回归每个元素的每个点,并提出了针对地图元素的等价定义问题。
Motivation: 针对当下地图元素的定义中存在的歧义性,提出了基于排列的方案;遵循DETR的范式,将在线地图构造任务提到了实时级的水平。
Result: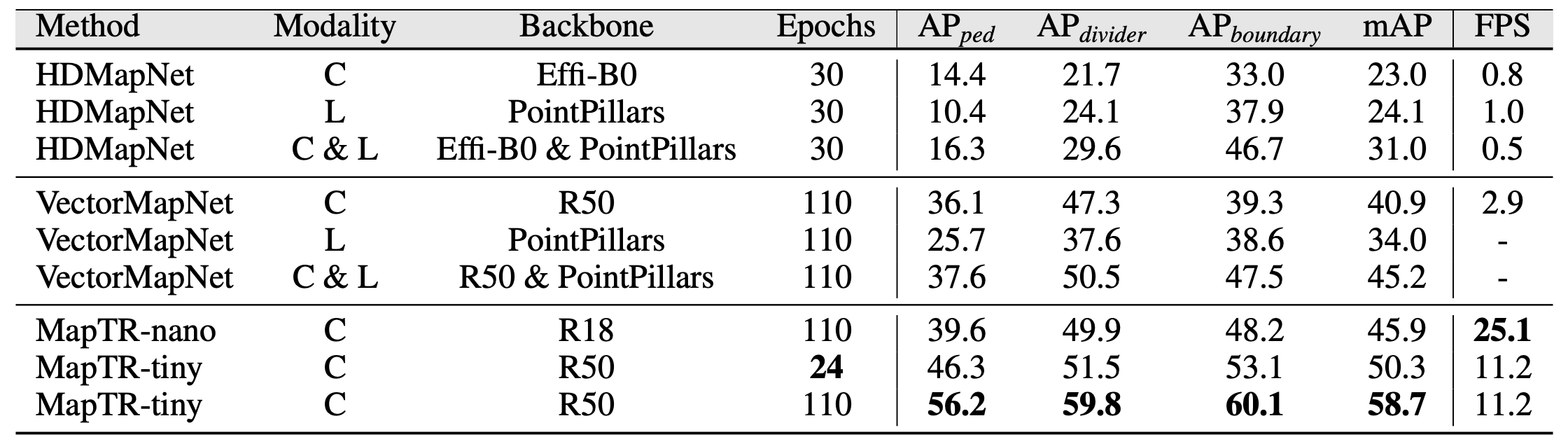
注:MapTR是目前Online HD Map Construction任务的SOTA,另外写了一篇MapTR论文与代码解读给出了详细的介绍。
Pipeline
MapTR是一个完全的set prediction任务,几乎可以看作是BEVFormer+DETR head的方案。
MapTR将每个地图元素视为一个有一组等价排列方式的点集,首先采用常规的view transformation方案将6帧图像转到BEV视角下,然后使用层级式的二分匹配设计,依次进行instance-level、point-level的匹配,其pipeline如图8所示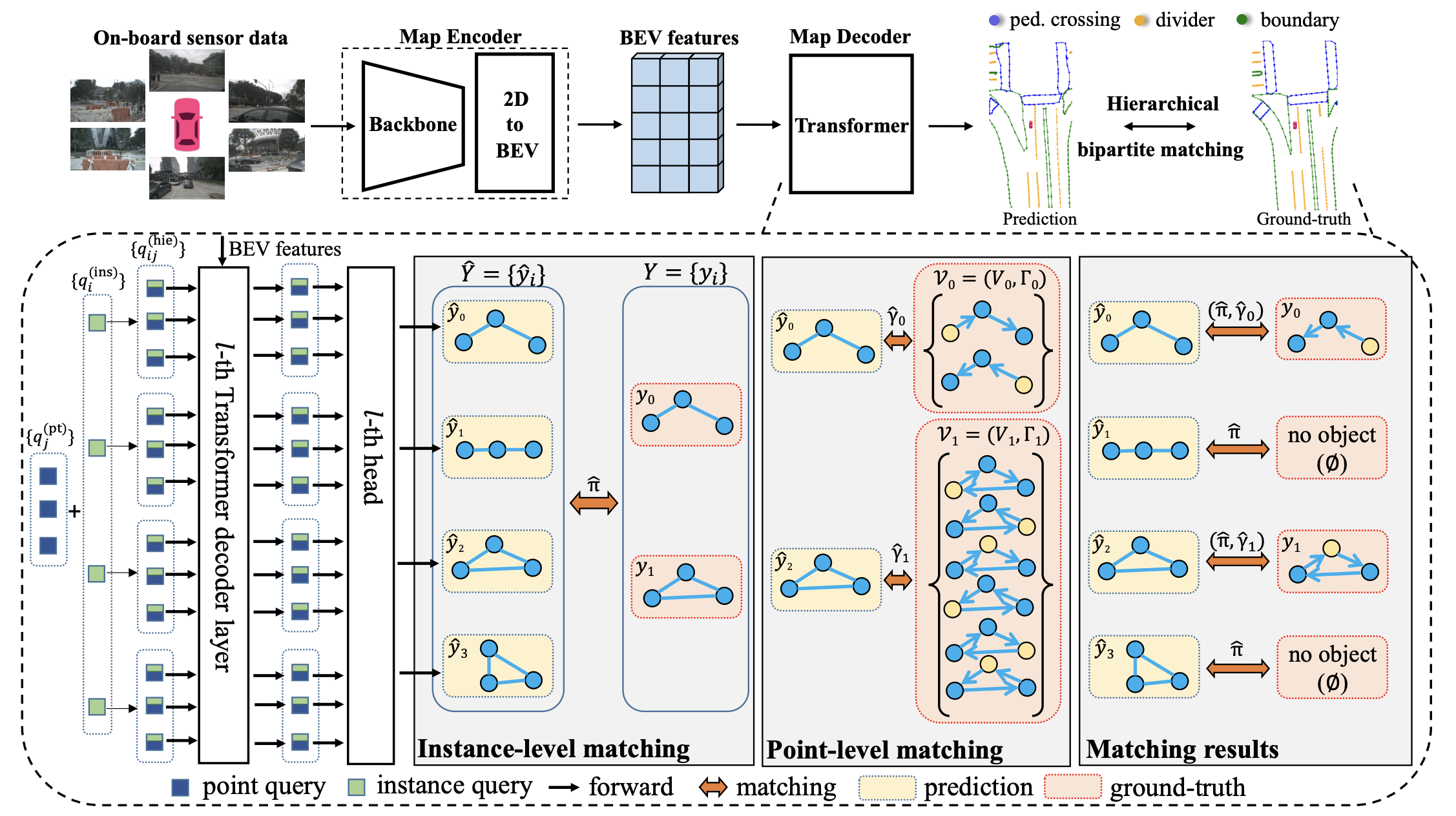
- Map Encoder
这里用的应该是作者实验室团队的GKT,原理和BEVFormer的Spatial cross attention基本一样。实际上可以根据自己的需要替换成其他模块,作者在消融实验中也给出了不同的视角转换模块的性能对比,比较有参考意义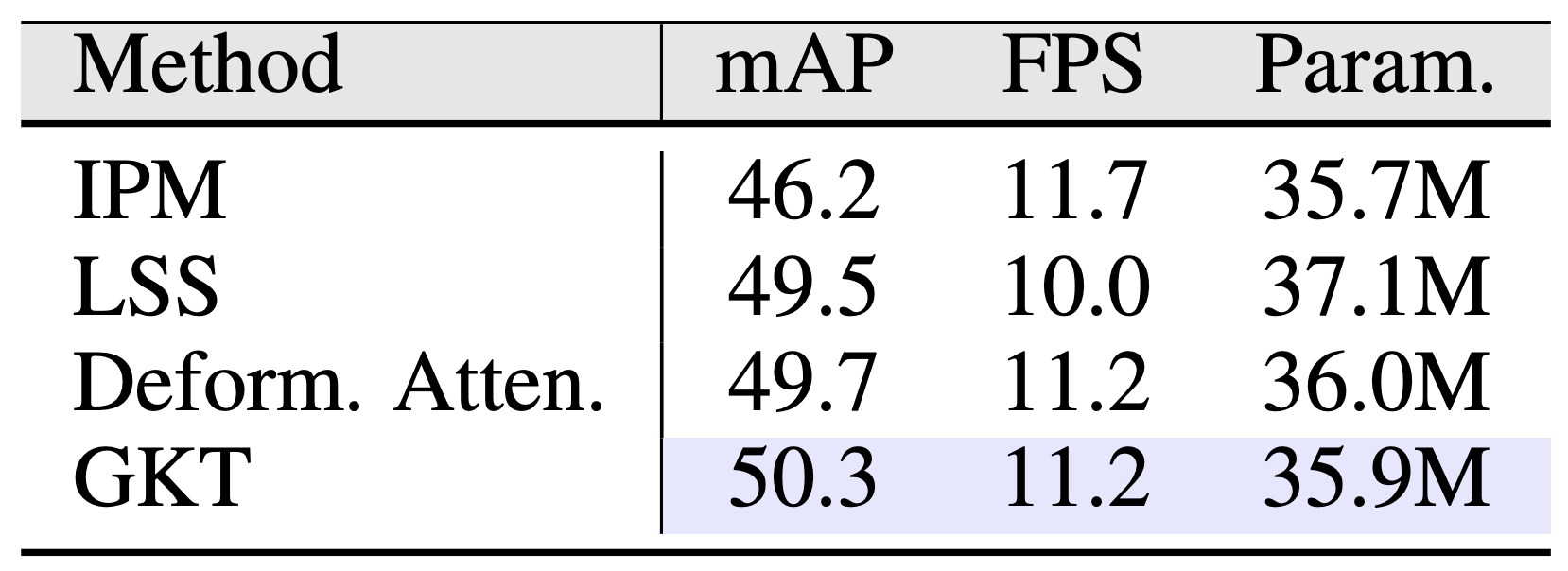
- Map Decoder
DETR的Decoder设计,比较特别的是MapTR在初始化每个Query的时候就直接赋予了结构化关系,也即文中所说的hierarchical query,因此能够直接回归每个地图元素的每个点。其注意力操作中的cross attention也是比较常规的deformable attention,即每个query只与其对应的参考点位置的BEV特征进行交互。这样做的好处就是避免了类似VectorMapNet中需要两阶段才能得到的完整的矢量化的地图数据。 - Hierarchical Match
根据之前的操作,已经能够得到多个由有序的点集组成的地图元素,这个模块就是解决有序点集与真值的匹配问题。如前文所述,每个Query在初始化的时候就已经固定了其所属的instance信息,因此这里的匹配包含两部分内容:元素匹配和元素中点的匹配。由于真值和推理结果都是有序的点集,可以直接将元素中所有对应点的距离累加作为两个元素之间的差异。
在这个部分,MapTR提出了它们的核心思路,也就是对于地图构造任务来说,真值中有序点集的顺序并不是唯一正确的顺序。因此,MapTR扩展了单个有序的真值点集为其等价定义类。根据预测值与等价定义类的二分匹配结果确定最终的匹配。
loss
MapTR损失由分类损失、点对点的损失和方向损失三部分组成
分类损失是Focal loss。点对点的损失限制的是每个点的位置,使用的是Manhattan距离。点对点的损失仅限制折线和多边形的节点,不考虑边(相邻点之间的连接线)。但是对于地图元素来说,边的方向也同样重要,方向损失使用余弦相似度进行度量。
优点
- SOTA,精度高的同时速度非常快
- 提出了地图构造问题中组成每个元素的有序点集的排列等价性,从实验中可以看出有效提升了模型性能。
缺点
- 等数量插值,模型性能会受每个元素的点集数量的影响
- 元素之间、元素内部的结构关系约束比较弱,可能因此导致模型收敛速度慢
[202301]InstaGraM
Title:InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
TL;DR: 分别预测vertex map和edge map,然后通过instance-level的图建模构造矢量化地图元素。
Motivation: 现有的方法要么依赖后处理,要么依赖自回归,速度都比较慢。(本文没有提及MapTR,实际上二者速度应该是差不多的,但是MapTR的精度更高)
Result: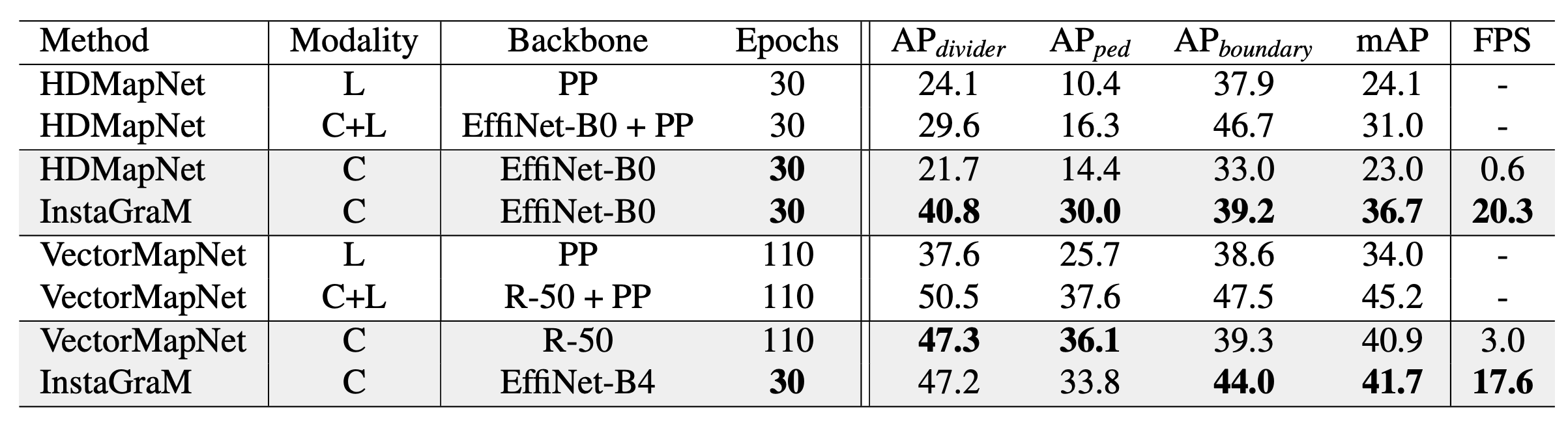
Pipeline
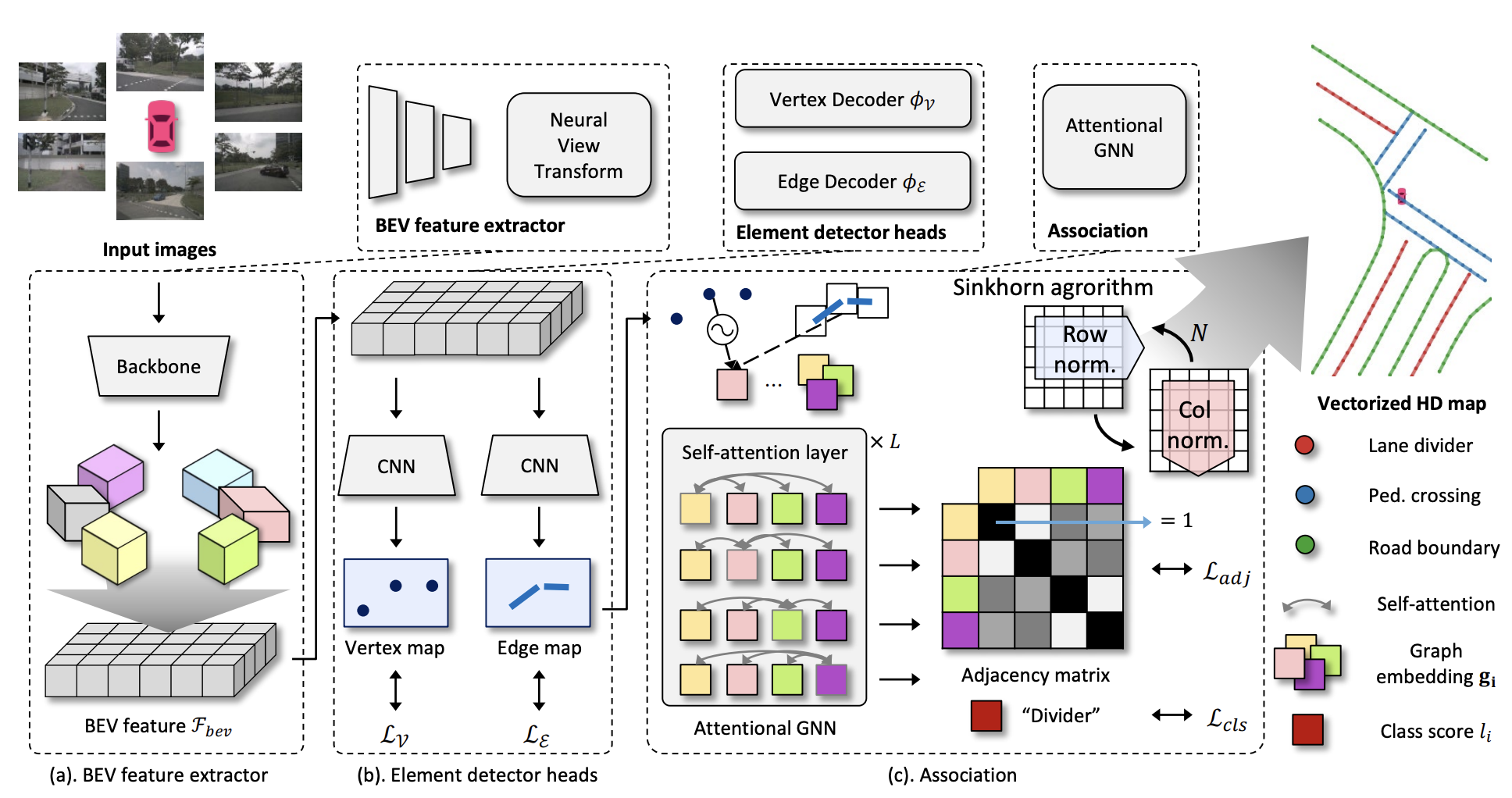
- BEV feature extractor
参考HDMapNet的IPM方式 - Element detector heads
使用两个CNN decoder分别提取vertecies和edge的特征信息。vertecies预测的是顶点的heatmap,edge预测的是distance transform map - Association
这部分是使用GNN关联上一个得到的vertecies和edge的信息。
优点
- 提出图建模的思想解决矢量地图构造问题
- 速度非常快
缺点
- 先检测点,再通过图连接,这种二阶段方式在交通密集的场景效果会比较差,缺乏一定的关联推理能力
- 代码未开源
性能评价指标
早期基于分割的方案使用的是IoU的评价指标,自VectorMapNet将该问题描述为检测问题后,比较常用的评价指标是基于距离的评价指标mAP。
判断正负样例使用的是几何相似性,使用的chamfer distance。chamfer distance衡量两个无序点集的相似性,考虑了元素点集的所有排列方式,公式定义如下
推理结果和真值都采样成100个点,分别在$\{0.5, 1.0, 1.5\}$距离阈值下计算AP。取各类别在各阈值下的平均值作为最终的结果。
参考
HDMapNet Paper
VectorMapNet Paper
MapTR Paper
InstaGraM Paper
https://zhuanlan.zhihu.com/p/574687904

