Fast-BEV论文解读
Fast-BEV
Fast-BEV的整体结构如图1所示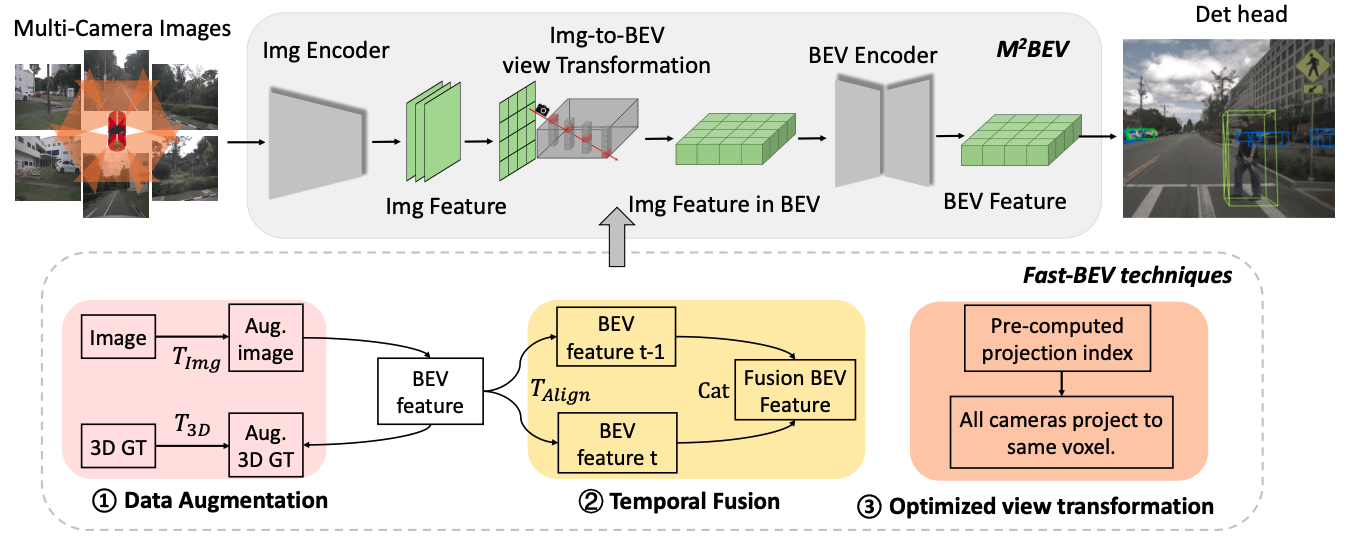
Fast-BEV是在M$^2$BEV的基础上,进行了三方面的改进
- 为了防止过拟合,在图像空间和BEV空间都进行了有力的数据增强策略
- 利用时序信息的多帧融合机制
- 部署友好的视角转换方案
前两方面改进实际上都是比较常见的,文中主要是第三点改进能够显著提高2D图像到3D特征的视角转换速度。M$^2$BEV假设沿着光线的深度分布是均匀的。基于此,一旦得到了相机的内部/外部参数,就可以很容易地知道2D到3D投影。由于这里没有使用可学习的参数,可以很容易地计算2D特征图上的点与BEV特征图之间的对应矩阵。
投影索引是从2D图像空间到3D体素空间的映射索引。由于该方案不依赖于数据相关的深度预测或变换器,所以投影索引对于每个输入都是相同的。因此,可以预先计算固定的投影索引并存储它。在推理阶段,可以通过查询查询表获得投影索引,这在边缘设备上是非常“便宜”的操作。此外,如果从单帧扩展到多帧,也可以轻松预先计算内在和外在参数并将其预先对齐到当前帧。

