Persformer论文与代码解读
Persformer
Persformer是一个针对3D车道线检测的模型,在介绍具体模型设计之前,由于3D Lane和HD Map Construction在一定程度上比较接近,顺便插播一下二者的异同
同:
- task的对象都包括车道线;
- 都得到的是车载坐标系下的结果,即包含从2D-3D的一个转换过程,而不同于传统的图像上的2D车道线检测/分割任务。
异:
- 3D Lane的数据集和HD Map Construction的数据集不太一样。前者主要是OpenLane等3D车道线数据集,这些数据集通常仅提供前视单目的图像,数据类别通常只有车道线、路沿线等长线性类别。后者主要是nuScenes数据集,nuScenes数据集提供周视多相机的图像,能够覆盖360度的视角,数据类别包括车道线、路沿线、人行横道等;
- 受制于上述数据集差异,3D Lane仅针对3D车道线,输出结果是单目视角的车道线每个位置的3D坐标;HD Map Construction通常包括车道线、路沿线和人性横道,输出结果是360度范围内每个元素每个位置的2D坐标(a.因为nuScenes只提供了BEV的2D坐标,并没有高度;b.Argoverse数据集虽然提供了周视3D地图元素标注,但是元素类别存在重合,即一个元素可能即是车道分界线也是路沿线,对模型结果有一定影响);
- 由于3D Lane仅针对3D车道线,基于这个task的模型常常采用基于anchor的方案,因为单个车道线不会与y轴同一位置有两个不同的交点,元素形状实际上比较理想的。但是HD Map Construction的地图元素十分“自由”,路沿线和人行横道都包括封闭图形,检测的难度更大,很难使用这种anchor封装;
- 3D Lane的数据集可以得到在图像上的2D标注结果,因此3D Lane的模型常常借助2D和3D联合检测的结果。正如前文所示,nuScenes只提供了BEV的2D坐标,并没有高度,因此无法得到图像上的2D信息,基本没有采用联合检测的方案。
以上差异导致两个task的模型设计非常不一样。
Persformer的整体思路简单来说就是使用 Transformer 进行2D 和 3D 车道线的联合检测,其整体结构如图1所示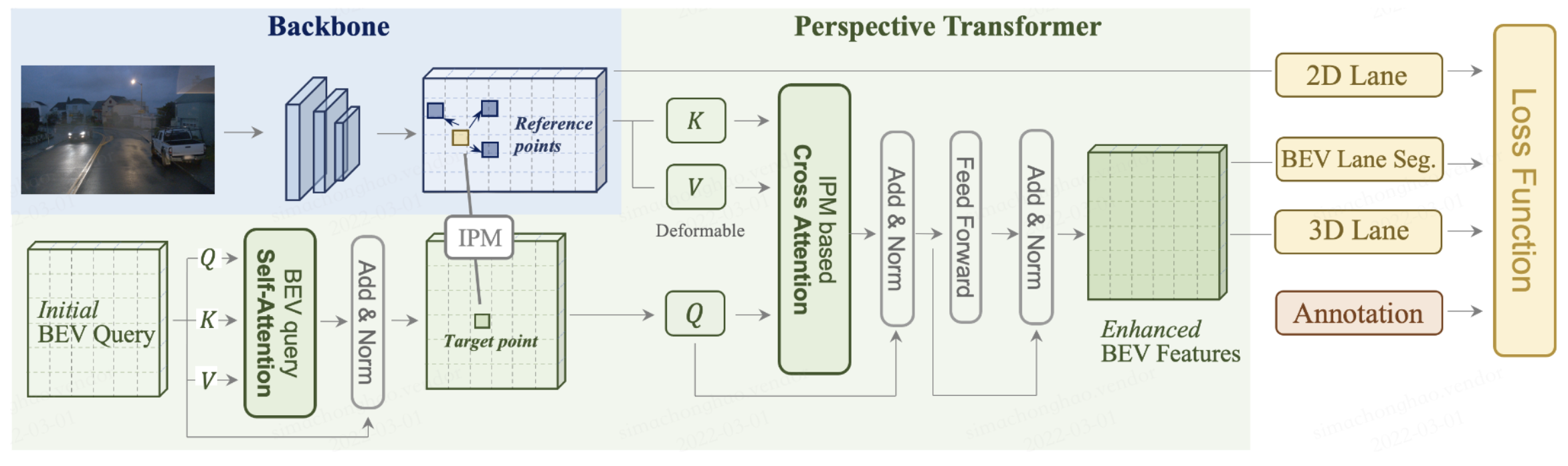
Persformer的核心是从前视图到 BEV 空间的空间特征变换,以便通过关注参考点周围的局部上下文,在目标点生成的 BEV 特征将更具代表性。Persformer由三个部分组成,backbone、Perspective Transformer和lane detection heads。backbone仍然是常规的ResNet,以下将详细介绍后两个部分。
Perspective Transformer
Persformer的视角转换模块依赖相机的内外参,这个模块和BEVFormer的思想基本一致。初始化BEV Queries,通过deformable attention的方式实现BEV Queries和对应的2D特征之间的交互。实现方式也遵循DETR的范式,包括self-attention和cross-attention两个部分。
cross-attention模块中,BEV空间中的点$(x, y)$通过中间态$(x’, y’)$投射前视图中的对应点$(u, v)$;通过学习偏移量,网络学习从绿色矩框到黄色目标参考点之间的映射,以及相关的蓝色框作为Transformer的key。图解如下图所示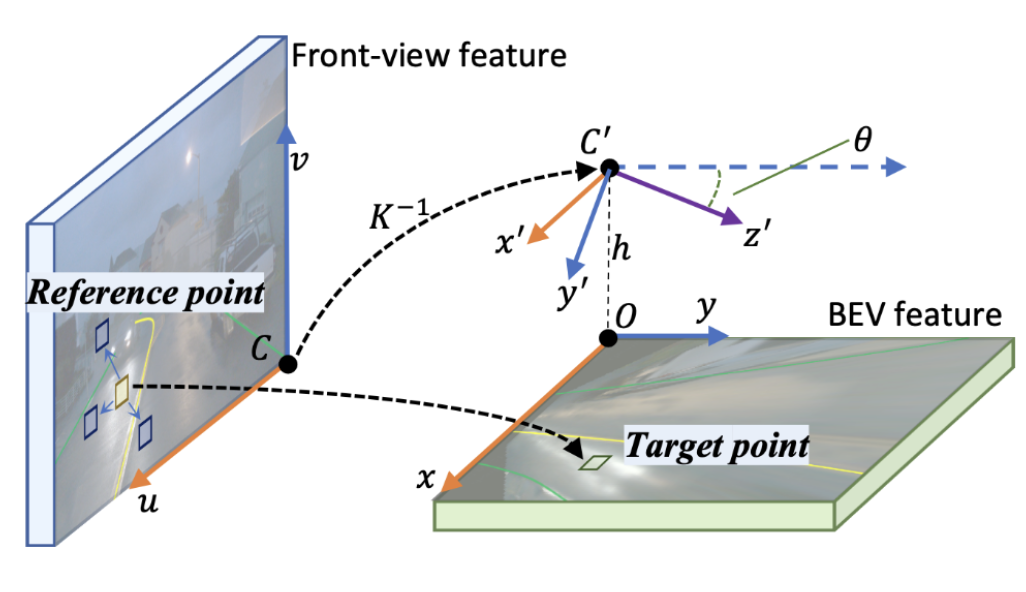
Lane detection Head
Unified Anchor Design
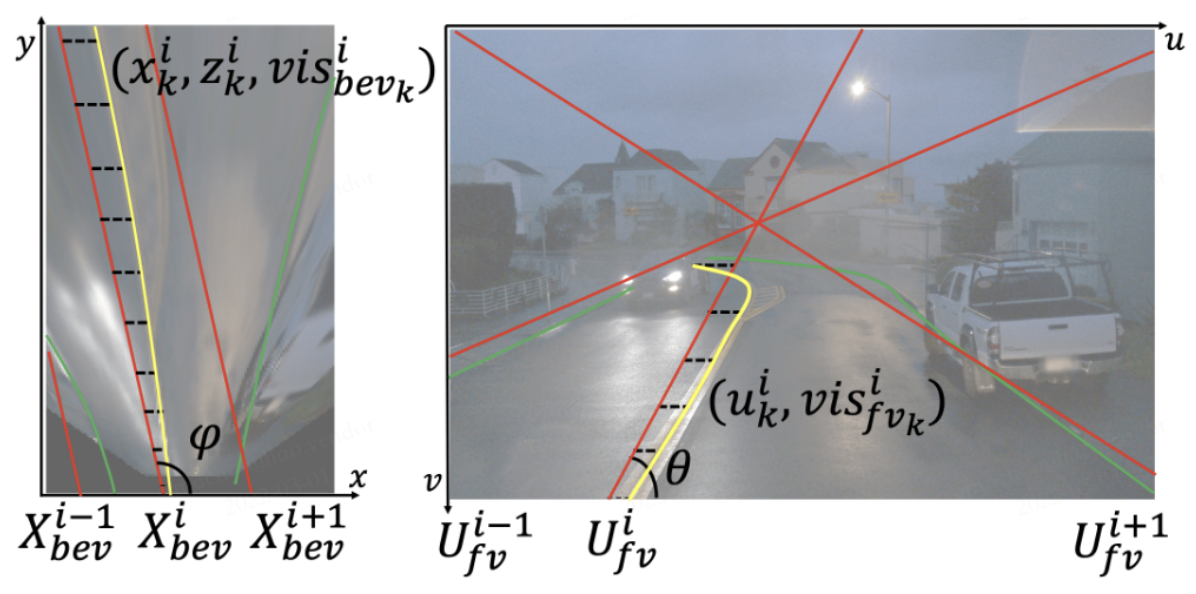
Unifying anchor design in 2D and 3D. We first put curated anchors (red) in the BEV space (left), then project them to the front view (right). Offset $x^i_k$ and $u^i_k$ (dashed line) are predicted to match ground truth (yellow and green) to anchors. The correspondence is thus built, and features are optimized together.
这个部分对于3D和2D的统一设计的方式写的有点模糊,官方的知乎文章也是有点粗糙的。博主本人也没仔细研究这一块的代码,就不做展开介绍了。
3D Lane Head
2D/3D 检测头参考的是LaneATT和3D-LaneNet,这里着重介绍3D lane head。
| 组件 | 类型 | tensor size |
|---|---|---|
| 卷积层 | 3*Conv2d(kerner_size=3)+9*Conv2d(kerner_size=5) | [B, 64, 50, 25]—>—[B, 64, 8, 25] |
| reshape | x = x.reshape(sizes[0], sizes[1] * sizes[2], sizes[3], 1) | [B, 64, 8, 25]—>—[B, 512, 25, 1] |
| 卷积层 | 2*Conv2d(kerner_size=5) | [B, 512, 25, 1]—>—[B, 30, 25, 1] |
| reshape | x = x.squeeze(-1).transpose(1, 2) | [B, 30, 25, 1]—>—[B, 25, 30] |
| sigmoid | x[:, :, :2 self.num_y_steps] = torch.sigmoid(x[:, :, :2 self.num_y_steps]) | [B, 25, 30] |
3D Lane Head Loss
- 针对车道线坐标偏移的预测,计算L1 loss(normalized的结果)
- 针对visibility的预测,计算CE loss
- 针对车道线类别的预测,计算CE loss

