本文对MapTR的论文和代码进行了解读。
本文主要改进的地方在于针对地图元素的数据结构进行了instance-point点集的层级式设计,模型直接预测了每个地图元素的点集,而非HDMapNet类的方法去预测分割的tensor。Nuscenes Map所提供的数据本身也就是点集的形式,以下将首先对Nuscenes Map数据集进行简要介绍。
Nuscenes Map
Nuscenes地图分为两个图层,几何图层和非几何图层,几何图层包括(polygon, line, node), 非几何图层包括(drivable_area, road_segment, road_block, lane, ped_crossing, walkway, stop_line, ‘carpark_area’, ‘road divider’, ‘lane divider’, ‘traffic light’)
下载Nuscenes Map expansion可以看到地图元素的细节描述,以下以expansion/boston-seaport.json为例进行具体分析
{
"polygon": [
{
"token": "1b161e64-fe37-4f3f-96db-299edefe9f8c",
"exterior_node_tokens": [
"ee85f1a6-38c4-4491-8a3b-93e1d5bf2911",
...
],
"holes": []
}
],
"line": [
{
"token": "7a8fcfed-9c66-475a-8dcf-9efe983acc98",
"node_tokens": [
"fde59d81-e200-4a78-80e7-b8044d417b02",
"0cffed4b-c5b7-4cd2-95ec-0d4252a1c896"
]
}
],
"node": [
{
"token": "16af4f78-e195-4954-bf2a-889e9fa4d751",
"x": 525.7599033618623,
"y": 752.3132939140847
}
],
...
}MapTR
We present Map TRansformer, for efficient online vectorized HD map construction. MapTR is a unified permutation-based modeling approach, i.e., modeling map element as a point set with a group of equivalent permutations, which avoids the definition ambiguity of map element and eases learning.
MapTR是一个基于排列的HD Map构造方法,它将每个地图元素视为有着一组等价排列方式的点集,通过这样的方式避免地图元素定义上的歧义。
The definition ambiguity of map element
地图元素可以抽象为多段线(车道线等)和多边形(人行横道等)两种。对于多段线而言,两个端点都可以视作起始点;对于多边形而言,从点集中任何一点以任意方向排列都是合理的。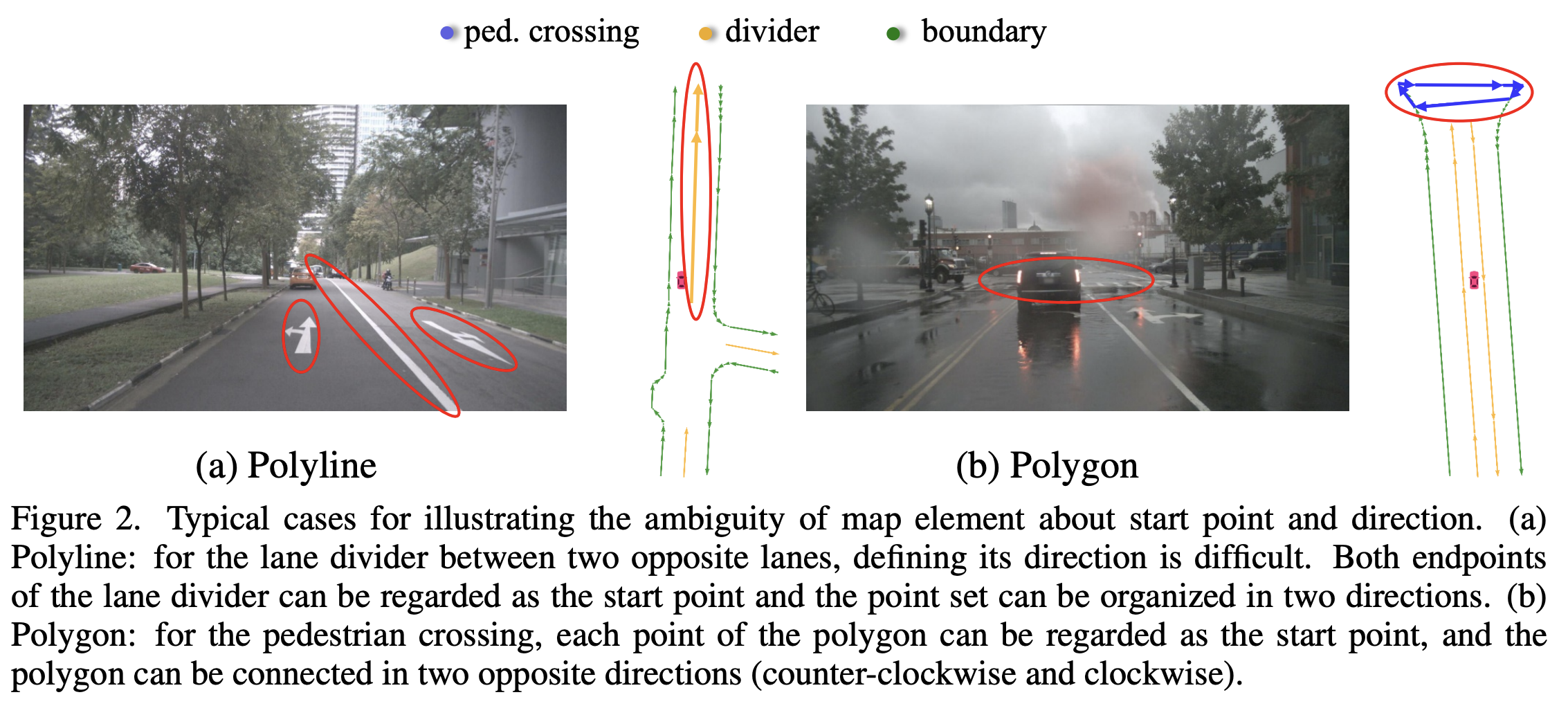
Permutation-based modeling of MapTR
为了弥补这种差距,MapTR使用$\mathcal{V}=(V,\Gamma)$建模每个地图元素,$V=\{v_j\}_{j=0}^{N_v-1}$表示该地图元素的点集,$\Gamma=\{\gamma_k \}$表示这个点集的一组等效的排列,包含所有可能的组织序列。
对于多段线而言,有两种等价的排列方式;对于多边形而言,有$2N_v$种等价的配列方式。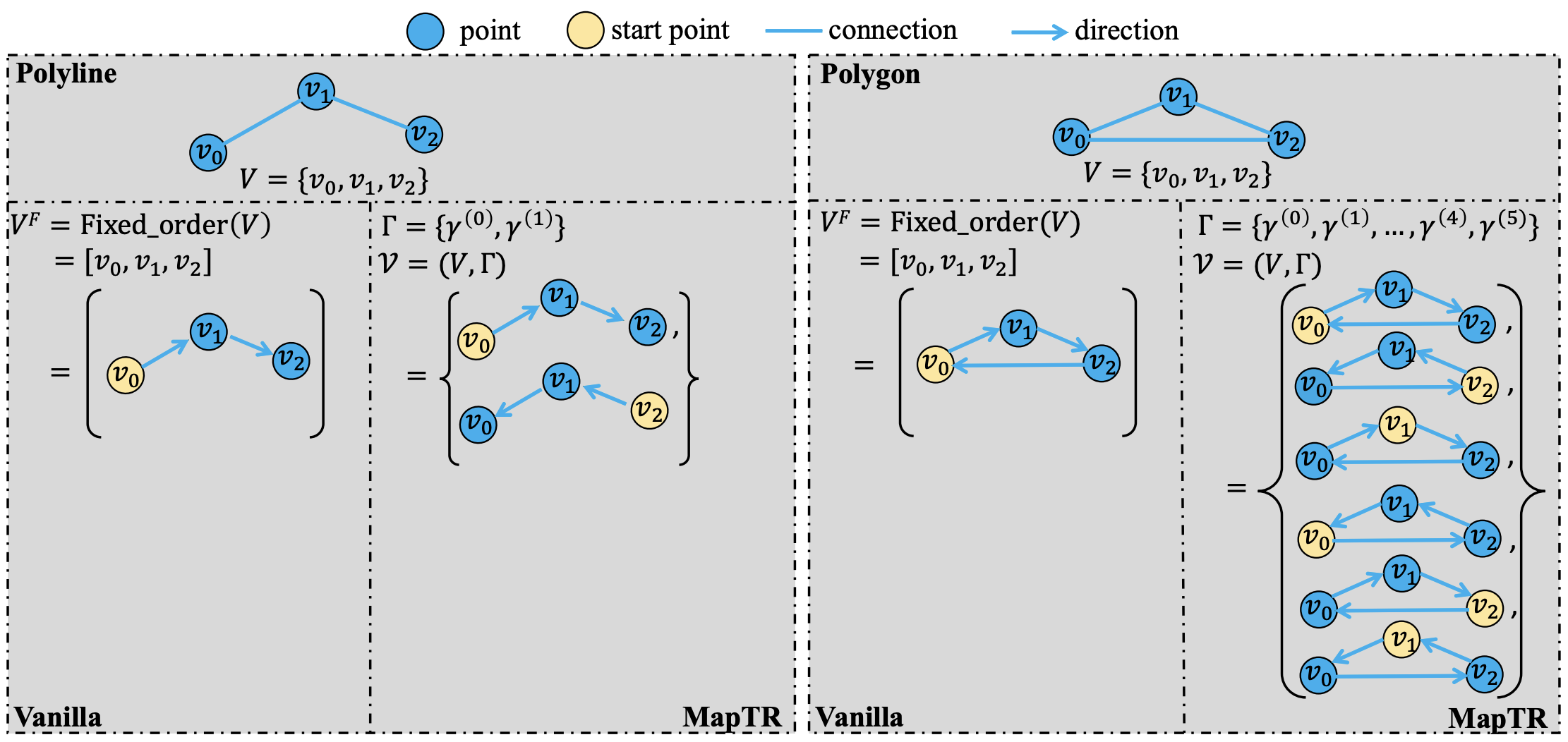
Hierarchical matching
在此基础上,MapTR进一步引入了层级式的二分匹配,依次执行instance-level和point-level的匹配。
instance-level的匹配是在预测的instance和真值的instance之间寻找一个最优的标签分配,参考DETR的方法使用的是匈牙利匹配算法。
得到instance-level的结果之后,使用point-level找到最优的点对点的匹配,利用 Manhattan 距离度量。
Overall architecture of MapTR
MapTR的整体结构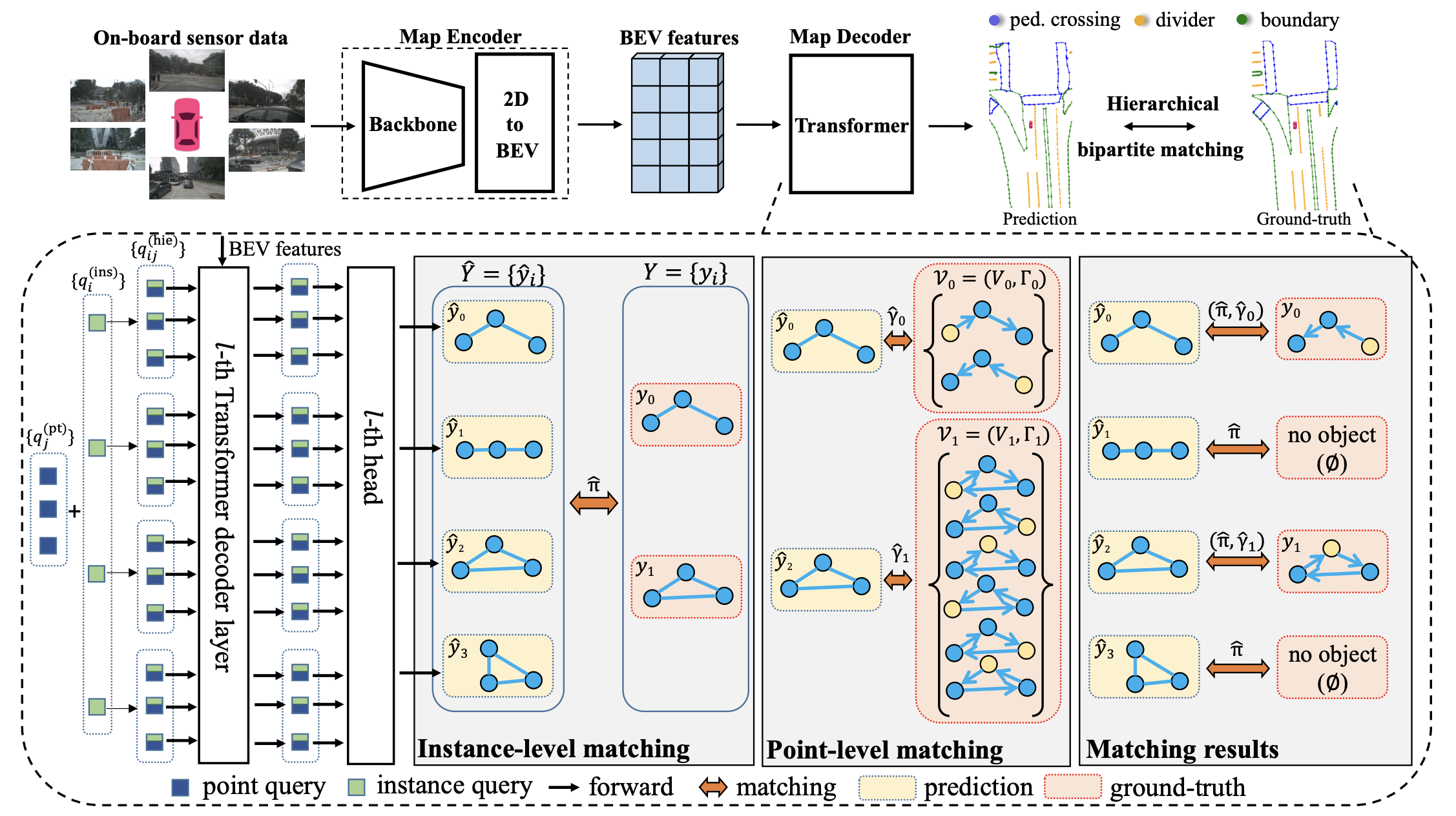
代码
代码模块划分
| 论文模块 | 代码模块 | 子模块 | transformer layer | 具体类型 | 输入维度 | 输出维度 |
|---|---|---|---|---|---|---|
| MapEncoder | img_backbone | - | - | ResNet50 | [B, N, 3, 480, 800] | [B, N, 2048,15,25] |
| img_neck | - | - | FPN | [B, N, 2048,15,25] | [B, N, 256, 15, 25] | |
| MapTRHead | BEVFormerEncoder | BEVFormerLayer | BEVFormer | [N, 15*25, B, 256][B, 20000, 256] | [B, 20000, 256] | |
| MapDecoder | MapTRDecoder | DETRDecoderLayer | MultiHead Attention | [50*20, B, 256] [B, 20000, 256] | [N, 50*20, B, 256] | |
| Deformable Attention |
BEVFormerEncoder
def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False):
bs, num_cam, _, _, _ = mlvl_feats[0].shape # [B, N, 256, 15, 25]
pts_embeds = self.pts_embedding.weight.unsqueeze(0) # [1, 20, 512]
instance_embeds = self.instance_embedding.weight.unsqueeze(1) # [50, 1, 512]
object_query_embeds = (pts_embeds + instance_embeds).flatten(0, 1) # [1000, 512]
bev_queries = self.bev_embedding.weight # [200*100, 256]
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1) # [200*100, 2, 256]
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w), device=bev_queries.device) # [B, 200, 100]
bev_pos = self.positional_encoding(bev_mask).flatten(2).permute(2, 0, 1) # [200*100, B, 256]
# add can bus signals
can_bus = bev_queries.new_tensor([each['can_bus'] for each in kwargs['img_metas']]) # [B, 18]
can_bus = self.can_bus_mlp(can_bus)[None, :, :] # [1, B, 256]
bev_queries = bev_queries + can_bus * self.use_can_bus # [200*100, 2, 256]
feat_flatten = []
spatial_shapes = []
for lvl, feat in enumerate(mlvl_feats):
bs, num_cam, c, h, w = feat.shape
spatial_shape = (h, w)
feat = feat.flatten(3).permute(1, 0, 3, 2) # [N, B, 15*25, 256]
if self.use_cams_embeds: # camera的所有层级特征
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype)
feat = feat + self.level_embeds[None, None, lvl:lvl + 1, :].to(feat.dtype)
spatial_shapes.append(spatial_shape) # (15, 25)
feat_flatten.append(feat) # [N, B, 15*25, 256]
feat_flatten = torch.cat(feat_flatten, 2)
feat_flatten = feat_flatten.permute(0, 2, 1, 3) # (num_cam, H*W, bs, embed_dims)
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=bev_pos.device)
level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
bev_embed = self.encoder(
bev_queries, # Q [200*100, 2, 256]
feat_flatten, # K [N, 15*25, B, 256]
feat_flatten, # V
bev_h=bev_h,
bev_w=bev_w,
bev_pos=bev_pos, # [200*100, B, 256]
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
prev_bev=prev_bev,
shift=shift,
**kwargs
)
return bev_embed # [B, 20000, 256]def forward(self,
bev_query,
key,
value,
*args,
bev_h=None,
bev_w=None,
bev_pos=None,
spatial_shapes=None,
level_start_index=None,
valid_ratios=None,
prev_bev=None,
shift=0.,
**kwargs):
output = bev_query # [200*100, 2, 256]
intermediate = []
# reference point in 3D space, used in spatial cross-attention
# BEVFormer的设计,bev query查询reference point周围的RoI,每个query对应4个不同高度的point,每个point采样4个特征点。
# 通过只对参考点附近的位置进行采样,减少计算量,提高模型的收敛速度
ref_3d = self.get_reference_points(
bev_h, bev_w, self.pc_range[5]-self.pc_range[2], self.num_points_in_pillar, dim='3d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)
# reference point in 2D BEV space, used in temporal cross-attention
ref_2d = self.get_reference_points(
bev_h, bev_w, dim='2d', bs=bev_query.size(1), device=bev_query.device, dtype=bev_query.dtype)
reference_points_cam, bev_mask = self.point_sampling(ref_3d, self.pc_range, kwargs['img_metas'])
# reference_points_cam[N, B, 20000, 4, 2] 参考点的图像坐标,空间范围是20000*4
# bev_mask[N, B, 20000, 4] 3D点在图像上是否可见
bev_query = bev_query.permute(1, 0, 2)
bev_pos = bev_pos.permute(1, 0, 2)
bs, len_bev, num_bev_level, _ = ref_2d.shape
hybird_ref_2d = torch.stack([ref_2d, ref_2d], 1).reshape(bs*2, len_bev, num_bev_level, 2)
for lid, layer in enumerate(self.layers):
# DETR Decoder layer
output = layer(
bev_query,
key,
value,
*args,
bev_pos=bev_pos,
ref_2d=hybird_ref_2d,
ref_3d=ref_3d,
bev_h=bev_h,
bev_w=bev_w,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
reference_points_cam=reference_points_cam,
bev_mask=bev_mask,
prev_bev=prev_bev,
**kwargs)
bev_query = output
return output # [B, 20000, 256]MapTRDecoder
def forward(self,
mlvl_feats,
bev_queries,
object_query_embed,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
reg_branches=None,
cls_branches=None,
prev_bev=None,
**kwargs):
bev_embed = self.get_bev_features(...) # Encoder的输出 [B, 20000, 256]
bs = mlvl_feats[0].size(0)
query_pos, query = torch.split(object_query_embed, self.embed_dims, dim=1) # query_pos [1000, 256]
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1)
query = query.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_pos)
reference_points = reference_points.sigmoid()
init_reference_out = reference_points # [B, 1000, 2]
query = query.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
bev_embed = bev_embed.permute(1, 0, 2)
inter_states, inter_references = self.decoder(
query=query, # [1000, B, 256]
key=None,
value=bev_embed, # [20000, B, 256]
query_pos=query_pos, # [1000, B, 256]
reference_points=reference_points, # reference points of offset
reg_branches=reg_branches,
cls_branches=cls_branches,
spatial_shapes=torch.tensor([[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
inter_references_out = inter_references
return bev_embed, inter_states, init_reference_out, inter_references_out
# [20000, B, 256] [N, 1000, B, 256] [B, 1000, 2] [N, B, 1000, 2] 这里的N是层数def forward(self,
query,
*args,
reference_points=None,
reg_branches=None,
key_padding_mask=None,
**kwargs):
output = query # [1000, B, 256]
intermediate = []
intermediate_reference_points = []
for lid, layer in enumerate(self.layers):
reference_points_input = reference_points[..., :2].unsqueeze(2) # BS NUM_QUERY NUM_LEVEL 2
output = layer(
output,
*args,
reference_points=reference_points_input,
key_padding_mask=key_padding_mask,
**kwargs)
output = output.permute(1, 0, 2) # [B, 1000, 256]
# 根据预测的偏移量更新参考点的位置,给级联的下一个decoder layer提供参考点位置
if reg_branches is not None:
tmp = reg_branches[lid](output) # [B, 1000, 2]
assert reference_points.shape[-1] == 2
new_reference_points = torch.zeros_like(reference_points)
new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points[..., :2])
new_reference_points = new_reference_points.sigmoid()
reference_points = new_reference_points.detach() # [B, 1000, 2]
output = output.permute(1, 0, 2)
intermediate.append(output)
intermediate_reference_points.append(reference_points)
return torch.stack(intermediate), torch.stack(intermediate_reference_points)
# [N, 1000, B, 256] [N, B, 1000, 2] 推理结果处理
使用线性层将输出结果处理成points set的形式
bev_embed, hs, init_reference, inter_references = outputs # decoder的输出
hs = hs.permute(0, 2, 1, 3)
outputs_classes = []
outputs_coords = []
outputs_pts_coords = []
for lvl in range(hs.shape[0]): # 6
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)
outputs_class = self.cls_branches[lvl](hs[lvl].view(bs,self.num_vec, self.num_pts_per_vec,-1).mean(2)) # 线性层
tmp = self.reg_branches[lvl](hs[lvl]) # 线性层
assert reference.shape[-1] == 2
tmp[..., 0:2] += reference[..., 0:2]
tmp = tmp.sigmoid()
outputs_coord, outputs_pts_coord = self.transform_box(tmp)
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_pts_coords.append(outputs_pts_coord)
outputs_classes = torch.stack(outputs_classes)
outputs_coords = torch.stack(outputs_coords)
outputs_pts_coords = torch.stack(outputs_pts_coords)
outs = {
'bev_embed': bev_embed, # [20000, B, 256]
'all_cls_scores': outputs_classes, # [N, B, 50, 3] 最多50个instance
'all_bbox_preds': outputs_coords, # [N, B, 50, 4] bounding box形式
'all_pts_preds': outputs_pts_coords, # [N, B, 50, 20, 2] 所有instance的points set,points set的长度固定
'enc_cls_scores': None,
'enc_bbox_preds': None,
'enc_pts_preds': None
}
return outsLoss计算
MapTR的损失函数由分类损失、point2point损失和方向损失三个部分组成
分类损失使用Focal loss
point2point损失使用曼哈顿距离
方向损失使用配对的边之间的余弦相似度
代码中实际由五个部分组成(decoder输出了六层的结果,实际只取了最后一层的loss)
| loss | type |
|---|---|
| loss_cls | Focal loss |
| loss_bbox | L1 loss |
| loss_iou | GIoU loss |
| loss_pts | pts L1 loss |
| loss_dir | pts dir cos loss |

