本文基于BEVDET对MMDet3D框架进行了介绍
0.MMDetection3D简介
选择MMDet3D的原因
- MMDetection3D 支持_VoteNet_,_ MVXNe__t_,_PointPillars_等多种算法,覆盖了单模态和多模态检测,室内和室外场景SOTA; 还可以直接使用训练MMDetection里面的所有300+模型和40+算法,支持算法的数量和覆盖方向为3D检测代码库之最。
- MMDetection3D 支持_SUN RGB-D_, _ScanNet_, _nuScenes_, _Lyft_和_KITTI_共5个主流数据集,支持的数据集数量为3D检测代码库之最。
- MMDetection3D 拥有最快的训练速度,支持pip install一键安装,简单易用。
1.BEVDET网络框架
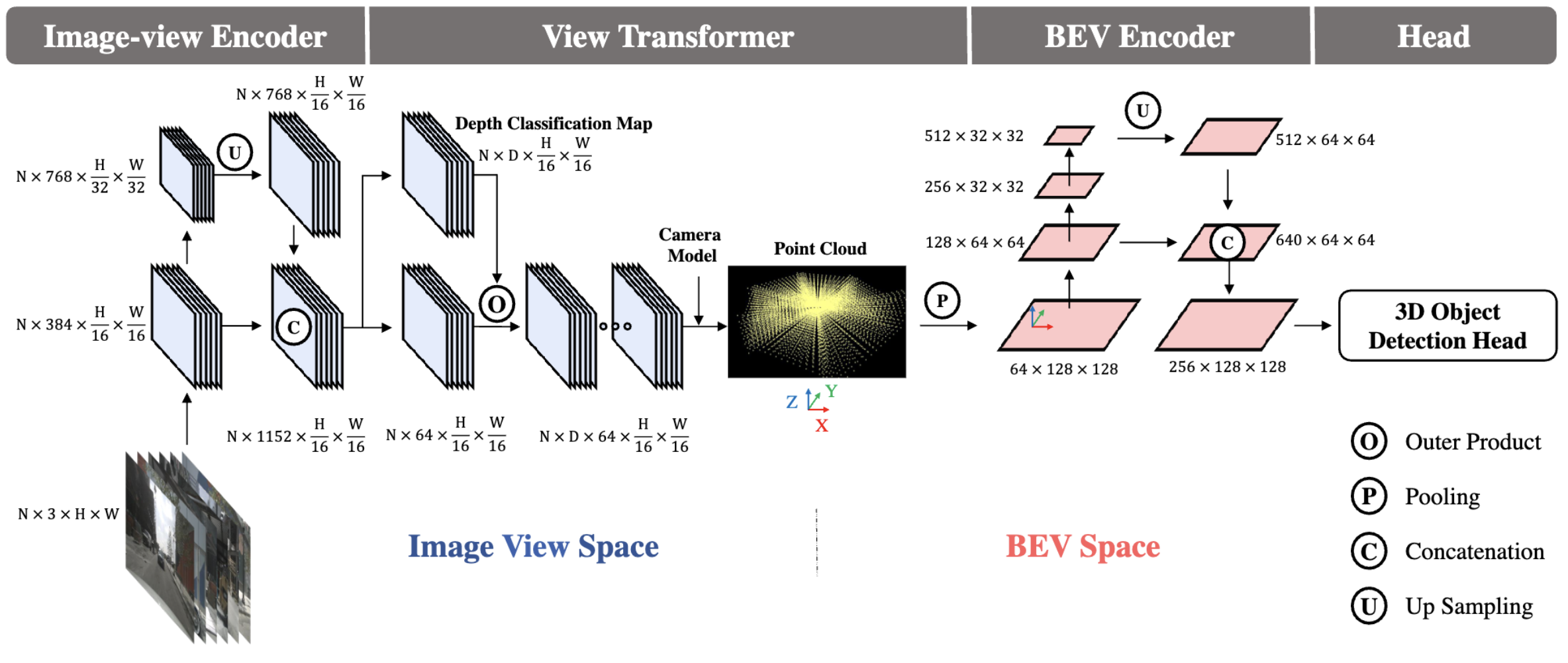
2.基于MMDet3D的BEVDET代码框架
2.1数据预处理
2.1.1 数据集定义
MMDet3D支持_SUN RGB-D_, _ScanNet_, _nuScenes_, _Lyft_和_KITTI_共5个主流数据集。对于上述数据集之外的公开数据集或者自定义数据集,可以通过继承 Custom3DDataset 来实现新的数据集类,并重载相关的方法,如 BEVDETNuScenesDataset数据集所示,该文件位于/mmdet3d/datasets/bevdet_nuscenes_dataset.py。
数据集类中主要提供加载标注数据、转换数据格式、验证模型结果、定义数据集处理流程等相关功能。
import mmcv
import torch
import numpy as np
import tempfile
from nuscenes.utils.data_classes import Box as NuScenesBox
from os import path as osp
from mmdet.datasets import DATASETS
from ..core import show_result
from ..core.bbox import Box3DMode, Coord3DMode, LiDARInstance3DBoxes
from .custom_3d import Custom3DDataset
from .pipelines import Compose
@DATASETS.register_module()
class BEVDETNuScenesDataset(Custom3DDataset):
def __init__(self):
pass
def load_annotations(self, ann_file):
"""Load annotations from ann_file."""
pass
def _format_bbox(self, results, jsonfile_prefix=None):
"""Convert the results to the standard format."""
pass
def evaluate(self):
"""Evaluation in BEVDETNuScenesDataset protocol."""
pass
def format_results(self, results, jsonfile_prefix=None):
"""Format the results to json"""
pass
def _build_default_pipeline(self):
"""Build the default pipeline for this dataset."""新增自定义数据集
在 /mmdet3d/datasets/my_dataset.py 中创建一个新的数据集类来进行数据的加载,如下所示。
import numpy as np
from os import path as osp
from mmdet3d.core import show_result
from mmdet3d.core.bbox import DepthInstance3DBoxes
from mmdet.datasets import DATASETS
from .custom_3d import Custom3DDataset
@DATASETS.register_module()
class MyDataset(Custom3DDataset):
CLASSES = ('cabinet', 'bed', 'chair', 'sofa', 'table', 'door', 'window',
'bookshelf', 'picture', 'counter', 'desk', 'curtain',
'refrigerator', 'showercurtrain', 'toilet', 'sink', 'bathtub',
'garbagebin')
def __init__(self,
data_root,
ann_file,
pipeline=None,
classes=None,
modality=None,
box_type_3d='Depth',
filter_empty_gt=True,
test_mode=False):
super().__init__(
data_root=data_root,
ann_file=ann_file,
pipeline=pipeline,
classes=classes,
modality=modality,
box_type_3d=box_type_3d,
filter_empty_gt=filter_empty_gt,
test_mode=test_mode)
def get_ann_info(self, index):
# 通过下标来获取标注信息,evalhook 也能够通过此接口来获取标注信息
info = self.data_infos[index]
if info['annos']['gt_num'] != 0:
gt_bboxes_3d = info['annos']['gt_boxes_upright_depth'].astype(
np.float32) # k, 6
gt_labels_3d = info['annos']['class'].astype(np.int64)
else:
gt_bboxes_3d = np.zeros((0, 6), dtype=np.float32)
gt_labels_3d = np.zeros((0, ), dtype=np.int64)
# 转换为目标标注框的结构
gt_bboxes_3d = DepthInstance3DBoxes(
gt_bboxes_3d,
box_dim=gt_bboxes_3d.shape[-1],
with_yaw=False,
origin=(0.5, 0.5, 0.5)).convert_to(self.box_mode_3d)
pts_instance_mask_path = osp.join(self.data_root,
info['pts_instance_mask_path'])
pts_semantic_mask_path = osp.join(self.data_root,
info['pts_semantic_mask_path'])
anns_results = dict(
gt_bboxes_3d=gt_bboxes_3d,
gt_labels_3d=gt_labels_3d,
pts_instance_mask_path=pts_instance_mask_path,
pts_semantic_mask_path=pts_semantic_mask_path)
return anns_results
修改配置文件来调用 MyDataset 数据集类,如下所示。
dataset_A_train = dict(
type='MyDataset',
ann_file = 'annotation.pkl',
pipeline=train_pipeline
)2.1.2 数据预处理流程
数据预处理流程和数据集之间是互相分离的两个部分,通常数据集定义了如何处理标注信息,而数据预处理流程定义了准备数据项字典的所有步骤。数据集预处理流程包含一系列的操作,每个操作将一个字典作为输入,并输出应用于下一个转换的一个新的字典。
图2是一个最经典的数据集预处理流程,其中蓝色框表示预处理流程中的各项操作。随着预处理的进行,每一个操作都会添加新的键值(图中标记为绿色)到输出字典中,或者更新当前存在的键值(图中标记为橙色)。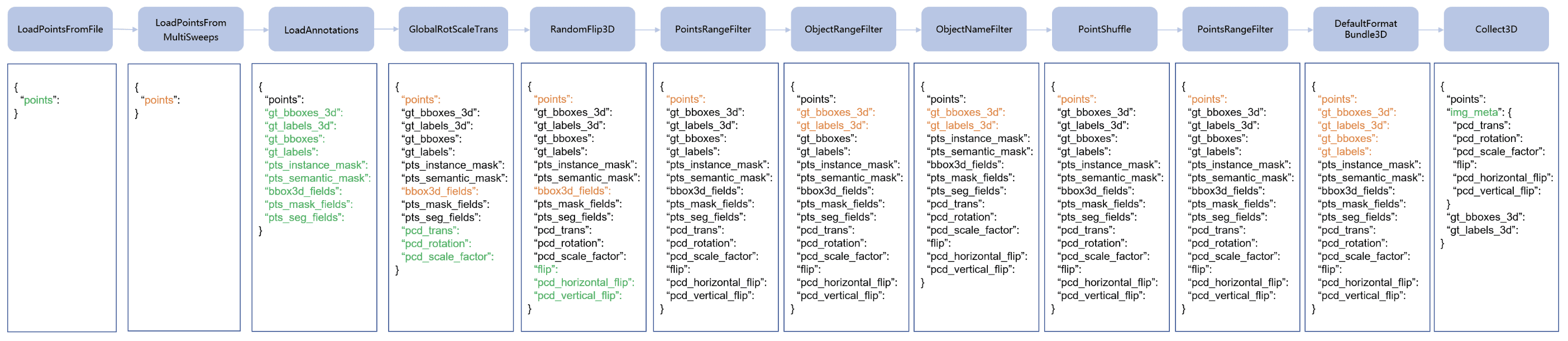
预处理流程中的各项操作主要分为数据加载、预处理、格式化、测试时的数据增强。以BEVDET为例,我们对预处理流程中各项操作进行具体的分析。
train_pipeline = [
dict(type='LoadMultiViewImageFromFiles_BEVDet', is_train=True, data_config=data_config),
dict(type='LoadPointsFromFile',
coord_type='LIDAR',
load_dim=5,
use_dim=5,
file_client_args=file_client_args),
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
dict(type='GlobalRotScaleTrans',
rot_range=[-0.3925, 0.3925],
scale_ratio_range=[0.95, 1.05],
translation_std=[0, 0, 0],
update_img2lidar=True),
dict(type='RandomFlip3D',
sync_2d=False,
flip_ratio_bev_horizontal=0.5,
flip_ratio_bev_vertical=0.5,
update_img2lidar=True),
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
dict(type='ObjectNameFilter', classes=class_names),
dict(type='DefaultFormatBundle3D', class_names=class_names),
dict(type='Collect3D', keys=['img_inputs', 'gt_bboxes_3d', 'gt_labels_3d'],
meta_keys=('filename', 'ori_shape', 'img_shape', 'lidar2img',
'depth2img', 'cam2img', 'pad_shape',
'scale_factor', 'flip', 'pcd_horizontal_flip',
'pcd_vertical_flip', 'box_mode_3d', 'box_type_3d',
'img_norm_cfg', 'pcd_trans', 'sample_idx',
'pcd_scale_factor', 'pcd_rotation', 'pts_filename',
'transformation_3d_flow', 'img_info'))
]上述流程中涉及到的各项操作及其在MMDet3D框架下的实际位置如表1所示。Collect3D最后返回的img_meta包含模型输入的全部数据。
表1 BEVDET相关数据处理操作
| 操作项 | 数据处理操作 | 功能 | 代码位置 |
|---|---|---|---|
| 数据加载 | LoadMultiViewImageFromFiles_BEVDet | 加载六个相机的单帧图像,进行图像的缩放和裁剪操作等 | /mmdet3d/datasets/pipelines/loading.py |
| LoadPointsFromFile | 加载LiDAR点云(如果不需要点云数据可以不加载) | ||
| LoadAnnotations3D | 加载标注数据 | ||
| 数据预处理 | GlobalRotScaleTrans | 对于点云数据的旋转、平移、缩放 | /mmdet3d/datasets/pipelines/transforms_3d.py |
| RandomFlip3D | 翻转点云和目标框 | ||
| ObjectRangeFilter | 根据范围过滤目标框 | ||
| ObjectNameFilter | 根据类别过滤目标框 | ||
| 格式化 | DefaultFormatBundle3D | 格式化真值数据 | /mmdet3d/datasets/pipelines/formating.py |
| Collect3D | 添加img_meta (由 meta_keys 指定的键值构成的 img_meta),移除所有除 keys 指定的键值以外的其他键值 |
新增自定义数据处理方法
在 /mmdet3d/datasets/pipelines/my_pipeline.py中写入新的数据集预处理方法,该预处理方法的输入和输出均为字典
from mmdet.datasets import PIPELINES
@PIPELINES.register_module()
class MyTransform:
def __call__(self, results):
results['dummy'] = True
return results在/mmdet3d/datasets/pipelines/init.py 中导入新的数据处理方法
from .my_pipeline import MyTransform在配置文件中使用该数据预处理方法
train_pipeline = [
dict(
type='LoadPointsFromFile',
load_dim=5,
use_dim=5,
file_client_args=file_client_args),
"""..."""
dict(type='MyTransform'),
"""..."""
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
]2.2模型
2.2.1 配置模型结构
MMDet3D使用config文件配置模型结构,BEVDET-sttiny版本的模型配置部分如下
model = dict(type='BEVDet',
img_backbone=dict(type='SwinTransformer',
pretrained='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth',
pretrain_img_size=224,
embed_dims=96,
patch_size=4,
window_size=7,
mlp_ratio=4,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
strides=(4, 2, 2, 2),
out_indices=(2, 3,),
qkv_bias=True,
qk_scale=None,
patch_norm=True,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.0,
use_abs_pos_embed=False,
act_cfg=dict(type='GELU'),
norm_cfg=dict(type='LN', requires_grad=True),
pretrain_style='official',
output_missing_index_as_none=False),
img_neck=dict(type='FPN_LSS',
in_channels=384+768,
out_channels=512,
extra_upsample=None,
input_feature_index=(0,1),
scale_factor=2),
img_view_transformer=dict(type='ViewTransformerLiftSplatShoot', grid_config=grid_config, data_config=data_config, numC_Trans=numC_Trans),
img_bev_encoder_backbone = dict(type='ResNetForBEVDet', numC_input=numC_Trans),
img_bev_encoder_neck = dict(type='FPN_LSS', in_channels=numC_Trans*8+numC_Trans*2, out_channels=256),
pts_bbox_head=dict(type='CenterHeadBEVDet',
in_channels=256,
tasks=[dict(num_class=1, class_names=['car']),
dict(num_class=2, class_names=['truck', 'construction_vehicle']),
dict(num_class=2, class_names=['bus', 'trailer']),
dict(num_class=1, class_names=['barrier']),
dict(num_class=2, class_names=['motorcycle', 'bicycle']),
dict(num_class=2, class_names=['pedestrian', 'traffic_cone']),
],
common_heads=dict(reg=(2, 2), height=(1, 2), dim=(3, 2), rot=(2, 2), vel=(2, 2)),
share_conv_channel=64,
bbox_coder=dict(type='CenterPointBBoxCoder',
pc_range=point_cloud_range[:2],
post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
max_num=500,
score_threshold=0.1,
out_size_factor=8,
voxel_size=voxel_size[:2],
code_size=9),
separate_head=dict(type='SeparateHead', init_bias=-2.19, final_kernel=3),
loss_cls=dict(type='GaussianFocalLoss', reduction='mean'),
loss_bbox=dict(type='L1Loss', reduction='mean', loss_weight=0.25),
norm_bbox=True),
) # 省略了模型的训练和配置信息上述模块划分与论文中的模块划分基本一致,其对应关系以及在MMDet3D框架下的实际位置如表2所示
表2 BEVDET的模型配置
| 论文模块 | 代码模块 | Tensor Size | 类型 | 代码位置 | 原论文 |
|---|---|---|---|---|---|
| Image-view Encoder | img_backbone | [B, N, 3, 256, 704] $\downarrow$ [[B, N, 384, 16, 44], [B, N, 768, 8, 22]] | SwinTransformer | mmdet3d/models/backbones/swin.py | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
| img_neck | [[B, N, 384, 16, 44], [B, N, 768, 8, 22]]$\downarrow$[B, N, 512, 16, 44] | FPN_LSS | mmdet3d/models/necks/lss_fpn.py | Feature Pyramid Networks for Object Detection | |
| View Transformer | img_view_transformer | [B, N, 512, 16, 44]$\downarrow$[B, 64, 128, 128] | ViewTransformerLSS | mmdet3d/models/necks/view_transformer_bevdet_bevdepth.py | Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D |
| BEVEncoder | img_bev_encoder_backbone | [B, 64, 128, 128]$\downarrow$[[B, 128, 64, 64], [B, 256, 32, 32], [B, 512, 16, 16]] | ResNetForBevDet | mmdet3d/models/backbones/resnet.py | Deep Residual Learning for Image Recognition |
| img_bev_encoder_neck | [[B, 128, 64, 64], [B, 256, 32, 32], [B, 512, 16, 16]]$\downarrow$[B, 256, 128, 128] | FPN_LSS | mmdet3d/models/necks/lss_fpn.py | Feature Pyramid Networks for Object Detection | |
| Head | pts_bbox_head | [B, 256, 128, 128]$\downarrow$[B, …, 128, 128] | CenterHeadBEVDet | mmdet3d/models/dense_heads/centerpoint_head_bevdet.py | Center-based 3D Object Detection and Tracking |
2.2.2 模型的各个组件
MMDet3D通常把模型的各个组成成分分成6种类型:
- 骨干网络(backbone):通常采用 FCN 网络来提取特征图,如 _ResNet _和 _SECOND_。
- 颈部网络(neck):位于 backbones 和 heads 之间的组成模块,如_ FPN_ 和 _SECONDFPN_。
- RoI 提取器(RoI extractor):用于从特征图中提取 RoI 特征的组成模块,如_ H3DRoIHead_ 和 _PartAggregationROIHead_。
- 编码器(encoder):包括 voxel layer、voxel encoder 和 middle encoder 等进入 backbone 前所使用的基于 voxel 的方法,如 _HardVFE_ 和_ PointPillarsScatter_。
- 检测头(head):用于特定任务的组成模块,如检测框的预测和掩码的预测。
- 损失函数(loss):heads 中用于计算损失函数的组成模块,如_ FocalLoss_、_L1Loss_ 和_ GHMLoss_。
Detector
对于3D检测模型,模型的总体框架由Dectectors定义,也即BEVDET-sttiny的配置文件中,model的type。在Detector中定义从输入的六张图像到模型输出结果的模型训练、测试的整体流程,包括对模型各子组件的调用。对于BEVDET-sttiny,其model的type为“BEVDet”,具体定义如下
import torch
from mmcv.runner import force_fp32
import torch.nn.functional as F
from mmdet.models import DETECTORS
from .centerpoint import CenterPoint
from .. import builder
@DETECTORS.register_module()
class BEVDet(CenterPoint):
def __init__(self, img_view_transformer, img_bev_encoder_backbone, img_bev_encoder_neck, **kwargs):
super(BEVDet, self).__init__(**kwargs)
self.img_view_transformer = builder.build_neck(img_view_transformer)
self.img_bev_encoder_backbone = builder.build_backbone(img_bev_encoder_backbone)
self.img_bev_encoder_neck = builder.build_neck(img_bev_encoder_neck)
def image_encoder(self, img):
imgs = img
B, N, C, imH, imW = imgs.shape
imgs = imgs.view(B * N, C, imH, imW)
x = self.img_backbone(imgs)
if self.with_img_neck:
x = self.img_neck(x)
_, output_dim, ouput_H, output_W = x.shape
x = x.view(B, N, output_dim, ouput_H, output_W)
return x
def bev_encoder(self, x):
x = self.img_bev_encoder_backbone(x)
x = self.img_bev_encoder_neck(x)
return x
def extract_img_feat(self, img, img_metas):
"""Extract features of images."""
x = self.image_encoder(img[0])
x = self.img_view_transformer([x] + img[1:])
x = self.bev_encoder(x)
return [x]
def extract_feat(self, points, img, img_metas):
"""Extract features from images and points."""
img_feats = self.extract_img_feat(img, img_metas)
pts_feats = None
return (img_feats, pts_feats)
def forward_train(self,
points=None,
img_metas=None,
gt_bboxes_3d=None,
gt_labels_3d=None,
gt_labels=None,
gt_bboxes=None,
img_inputs=None,
proposals=None,
gt_bboxes_ignore=None):
"""Forward training function."""
img_feats, pts_feats = self.extract_feat(
points, img=img_inputs, img_metas=img_metas)
assert self.with_pts_bbox
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d,
gt_labels_3d, img_metas,
gt_bboxes_ignore)
losses.update(losses_pts)
return losses
def forward_test(self, points=None, img_metas=None, img_inputs=None, **kwargs):
for var, name in [(img_inputs, 'img_inputs'), (img_metas, 'img_metas')]:
if not isinstance(var, list):
raise TypeError('{} must be a list, but got {}'.format(
name, type(var)))
num_augs = len(img_inputs)
if num_augs != len(img_metas):
raise ValueError(
'num of augmentations ({}) != num of image meta ({})'.format(
len(img_inputs), len(img_metas)))
if not isinstance(img_inputs[0][0], list):
img_inputs = [img_inputs] if img_inputs is None else img_inputs
points = [points] if points is None else points
return self.simple_test(points[0], img_metas[0], img_inputs[0], **kwargs)
else:
return self.aug_test(None, img_metas[0], img_inputs[0], **kwargs)
def simple_test(self, points, img_metas, img=None, rescale=False):
"""Test function without augmentaiton."""
img_feats, _ = self.extract_feat(points, img=img, img_metas=img_metas)
bbox_list = [dict() for _ in range(len(img_metas))]
bbox_pts = self.simple_test_pts(img_feats, img_metas, rescale=rescale)
for result_dict, pts_bbox in zip(bbox_list, bbox_pts):
result_dict['pts_bbox'] = pts_bbox
return bbox_listBackBone
BackBone通常是用于提取图像特征的骨干网络,一般是指定已内置的网络直接调用,包括_ResNET_、_SECOND_、_DLANet_等。对于BEVDET-sttiny,其img_backbone的type为“SwinTransformer”、img_bev_encoder_backbone的type为“ResNetForBEVDet”,后者的具体定义如下
from torch import nn
from mmdet.models.backbones.resnet import Bottleneck, BasicBlock
import torch.utils.checkpoint as checkpoint
from mmdet.models import BACKBONES
@BACKBONES.register_module()
class ResNetForBEVDet(nn.Module):
def __init__(self, numC_input, num_layer=[2,2,2], num_channels=None, stride=[2,2,2],
backbone_output_ids=None, norm_cfg=dict(type='BN'),
with_cp=False, block_type='Basic',):
super(ResNetForBEVDet, self).__init__()
assert len(num_layer)==len(stride)
num_channels = [numC_input*2**(i+1) for i in range(len(num_layer))] \
if num_channels is None else num_channels
self.backbone_output_ids = range(len(num_layer)) \
if backbone_output_ids is None else backbone_output_ids
layers = []
if block_type == 'BottleNeck':
curr_numC = numC_input
for i in range(len(num_layer)):
layer=[Bottleneck(curr_numC, num_channels[i]//4, stride=stride[i],
downsample=nn.Conv2d(curr_numC,num_channels[i],3,stride[i],1),
norm_cfg=norm_cfg)]
curr_numC= num_channels[i]
layer.extend([Bottleneck(curr_numC, curr_numC//4,
norm_cfg=norm_cfg) for _ in range(num_layer[i]-1)])
layers.append(nn.Sequential(*layer))
elif block_type == 'Basic':
curr_numC = numC_input
for i in range(len(num_layer)):
layer=[BasicBlock(curr_numC, num_channels[i], stride=stride[i],
downsample=nn.Conv2d(curr_numC,num_channels[i],3,stride[i],1),
norm_cfg=norm_cfg)]
curr_numC= num_channels[i]
layer.extend([BasicBlock(curr_numC, curr_numC, norm_cfg=norm_cfg) for _ in range(num_layer[i]-1)])
layers.append(nn.Sequential(*layer))
else:
assert False
self.layers = nn.Sequential(*layers)
self.with_cp = with_cp
def forward(self, x):
feats = []
x_tmp = x
for lid, layer in enumerate(self.layers):
if self.with_cp:
x_tmp = checkpoint.checkpoint(layer, x_tmp)
else:
x_tmp = layer(x_tmp)
if lid in self.backbone_output_ids:
feats.append(x_tmp)
return featsNeck
Neck一般是FPN,用于增强模型对不同scale的目标的处理能力,一般是指定已内置的网络直接调用,包括_ FPN_ 、_SECONDFPN_等。对于BEVDET-sttiny,其img_neck和img_bev_encoder_neck的type均为“FPN_LSS”,具体定义如下
import torch
import torch.nn as nn
from mmcv.cnn import build_norm_layer
from mmdet.models import NECKS
@NECKS.register_module()
class FPN_LSS(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=4,
input_feature_index=(0, 2),
norm_cfg=dict(type='BN'),
extra_upsample=2,
lateral=None):
super().__init__()
self.input_feature_index = input_feature_index
self.extra_upsample = extra_upsample is not None
self.up = nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=True)
channels_factor = 2 if self.extra_upsample else 1
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels * channels_factor, kernel_size=3, padding=1, bias=False),
build_norm_layer(norm_cfg, out_channels * channels_factor, postfix=0)[1],
nn.ReLU(inplace=True),
nn.Conv2d(out_channels * channels_factor, out_channels * channels_factor,
kernel_size=3, padding=1, bias=False),
build_norm_layer(norm_cfg, out_channels * channels_factor, postfix=0)[1],
nn.ReLU(inplace=True),
)
if self.extra_upsample:
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=extra_upsample , mode='bilinear', align_corners=True),
nn.Conv2d(out_channels * channels_factor, out_channels, kernel_size=3, padding=1, bias=False),
build_norm_layer(norm_cfg, out_channels, postfix=0)[1],
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=1, padding=0),
)
self.lateral= lateral is not None
if self.lateral:
self.lateral_conv = nn.Sequential(
nn.Conv2d(lateral, lateral,
kernel_size=1, padding=0, bias=False),
build_norm_layer(norm_cfg, lateral, postfix=0)[1],
nn.ReLU(inplace=True),
)
def forward(self, feats):
x2, x1 = feats[self.input_feature_index[0]], feats[self.input_feature_index[1]]
if self.lateral:
x2 = self.lateral_conv(x2)
x1 = self.up(x1)
x1 = torch.cat([x2, x1], dim=1)
x = self.conv(x1)
if self.extra_upsample:
x = self.up2(x)
return xHead
Head通常用于完成特定任务,loss函数和真值数据的处理也通常在这里完成,是稍微复杂一些的模块。MMDet3D已经提供的模块包括_FCOSMono3DHead_ 、_CenterHead_等,对于任务相近的模型,可以选择直接继承这些任务增加一些自定义的函数,也可以直接继承Head的基类实现。对于BEVDET-sttiny,其pts_bbox_head的type为“CenterHeadBEVDet”,具体定义如下
import copy
import torch
from mmcv.cnn import ConvModule, build_conv_layer
from mmcv.runner import BaseModule, force_fp32
from torch import nn
from mmdet3d.core import (circle_nms, draw_heatmap_gaussian, gaussian_radius, xywhr2xyxyr)
from mmdet3d.core.post_processing import nms_bev
from mmdet3d.models import builder
from mmdet3d.models.utils import clip_sigmoid
from mmdet.core import build_bbox_coder, multi_apply
from ..builder import HEADS, build_loss
@HEADS.register_module()
class CenterHeadBEVDet(BaseModule):
def __init__(self,
in_channels=[128],
tasks=None,
train_cfg=None,
test_cfg=None,
bbox_coder=None,
loss_cls=dict(type='GaussianFocalLoss', reduction='mean'),
loss_bbox=dict(
type='L1Loss', reduction='none', loss_weight=0.25),
separate_head=dict(
type='SeparateHead', init_bias=-2.19, final_kernel=3),
):
assert init_cfg is None, 'To prevent abnormal initialization ' \
'behavior, init_cfg is not allowed to be set'
super(CenterHeadBEVDet, self).__init__(init_cfg=init_cfg)
pass
def forward_single(self, x):
"""Forward function for CenterPoint."""
pass
def forward(self, feats):
"""Forward pass."""
return multi_apply(self.forward_single, feats)
def _gather_feat(self, feat, ind, mask=None):
"""Gather feature map"""
pass
def get_targets(self, gt_bboxes_3d, gt_labels_3d):
"""Generate targets"""
heatmaps, anno_boxes, inds, masks = multi_apply(
self.get_targets_single, gt_bboxes_3d, gt_labels_3d)
pass
def get_targets_single(self, gt_bboxes_3d, gt_labels_3d):
"""Generate training targets for a single sample"""
pass
@force_fp32(apply_to=('preds_dicts'))
def loss(self, gt_bboxes_3d, gt_labels_3d, preds_dicts, **kwargs):
"""Loss function for CenterHead"""
heatmaps, anno_boxes, inds, masks = self.get_targets(
gt_bboxes_3d, gt_labels_3d)
loss_dict = dict()
for task_id, preds_dict in enumerate(preds_dicts):
# heatmap focal loss
preds_dict[0]['heatmap'] = clip_sigmoid(preds_dict[0]['heatmap'])
num_pos = heatmaps[task_id].eq(1).float().sum().item()
loss_heatmap = self.loss_cls(
preds_dict[0]['heatmap'],
heatmaps[task_id],
avg_factor=max(num_pos, 1))
target_box = anno_boxes[task_id]
preds_dict[0]['anno_box'] = torch.cat(
(preds_dict[0]['reg'], preds_dict[0]['height'],
preds_dict[0]['dim'], preds_dict[0]['rot'],
preds_dict[0]['vel']),
dim=1)
ind = inds[task_id]
num = masks[task_id].float().sum()
pred = preds_dict[0]['anno_box'].permute(0, 2, 3, 1).contiguous()
pred = pred.view(pred.size(0), -1, pred.size(3))
pred = self._gather_feat(pred, ind)
mask = masks[task_id].unsqueeze(2).expand_as(target_box).float()
isnotnan = (~torch.isnan(target_box)).float()
mask *= isnotnan
code_weights = self.train_cfg.get('code_weights', None)
bbox_weights = mask * mask.new_tensor(code_weights)
if self.task_specific:
name_list = ['xy', 'z', 'whl', 'yaw', 'vel']
clip_index = [0, 2, 3, 6, 8, 10]
for reg_task_id in range(len(name_list)):
pred_tmp = pred[..., clip_index[reg_task_id]:clip_index[reg_task_id + 1]]
target_box_tmp = target_box[..., clip_index[reg_task_id]:clip_index[reg_task_id + 1]]
bbox_weights_tmp = bbox_weights[..., clip_index[reg_task_id]:clip_index[reg_task_id + 1]]
loss_bbox_tmp = self.loss_bbox(
pred_tmp, target_box_tmp, bbox_weights_tmp, avg_factor=(num + 1e-4))
loss_dict[f'%stask{task_id}.loss_%s' % (self.loss_prefix, name_list[reg_task_id])] = loss_bbox_tmp
else:
loss_bbox = self.loss_bbox(
pred, target_box, bbox_weights, avg_factor=(num + 1e-4))
loss_dict[f'task{task_id}.loss_bbox'] = loss_bbox
loss_dict[f'%stask{task_id}.loss_heatmap' % (self.loss_prefix)] = loss_heatmap
return loss_dict
def get_bboxes(self, preds_dicts, img_metas, img=None, rescale=False):
"""Generate bboxes from bbox head predictions"""
pass
def get_task_detections(self, num_class_with_bg, batch_cls_preds,
batch_reg_preds, batch_cls_labels, img_metas, task_id):
"""Rotate nms for each task"""
pass
新增自定义模型组件
此处以新增BackBone为例介绍如何新增自定义模型组件,其他组件的方法类似。
创建一个新文件mmdet3d/models/backbones/second.py
import torch.nn as nn
from ..builder import BACKBONES
@BACKBONES.register_module()
class SECOND(BaseModule):
def __init__(self, arg1, arg2):
pass
def forward(self, x): # should return a tuple
pass在/mmdet3d/models/backbones/init.py中导入该新增模块
from .second import SECOND在配置文件中使用新增的BackBone
model = dict(
...
backbone=dict(
type='SECOND',
arg1=xxx,
arg2=xxx),
...
