BEVFormer论文解读
BEVFormer
BEVFormer是自顶向下的稠密BEV特征建模。文章主要是把DETR3D思想中的3D特征反投影到2D图像上以得到密集、准确的BEV特征,从而能够在此基础上更好的进行检测、分割。如果说DETR3D是一种新的3D目标框的生成、特征交互方式,那么BEVFormer应该是一种更精准、更有效的BEV特征的生成方式。
BEVFormer整体结构
如下图所示,BEVformer框架也是从DETR3D发展而来,也是从bev空间的3D query出发,得到参考点和采样点,再通过多相机的内外参投影到多视角2D图片上,和相应特征进行交互。但DETR3D的object queries是稀疏的,每个query代表一个可能的目标框,而Bevformer的bev queries是稠密的,大小为$HWC$,$H,W$为设定的bev特征尺度,每个query代表一个网格(grid)的查询,这样可以得到稠密的bev特征。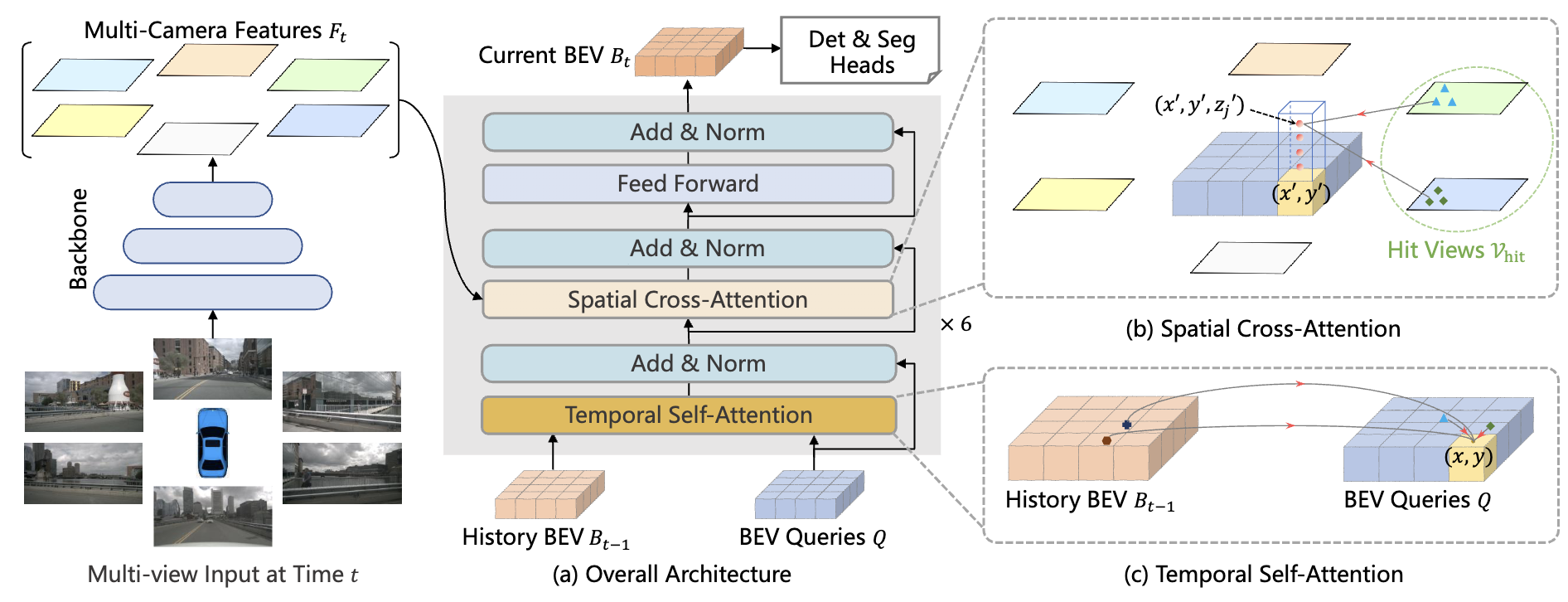
具体来说,BEV Queries是鸟瞰视角网格状的可学习参数。每个query都有对应的固定的空间位置,也即唯一对应的BEV坐标系的坐标,结合各相机的内外参,可以很容易的得到每个BEV Query对应的空间位置在各个视角的图像上的对应位置。图像特征的编码和常规的2D图像的处理没有什么区别,仍然是通过ResNet+FPN等类似的方案实现。整个BEVFormer对BEV特征的编码方式,主要由Spatial Cross-Attention和Temporal Self-Attention组成,共同作用得到时空信息都得到增强的BEV特征。
Spatial Cross-Attention
Spatial Cross-Attention是为了让每个随机初始化的BEV Query能够与其对应的图像特征进行交互,从而得到相应的空间信息。spatial cross-attention是基于Deformable Attention实现的,这是一个比较节省资源的交互方案,它能够让每个Query只与其对应的图像特征交互,而无需负担multi-head self attention进行全局交互所需的计算成本。
要实现BEV Queryies和2D的图像特征之间的交互,就需要找到每个Query与其对应的图像特征之间的对应关系。众所周知,从2D坐标到3D坐标的转换是一个不适定的问题,过去基于LSS的方式对每一个2D坐标进行了一个深度预测,深度的范围是$[2, 50)$。而将3D坐标转为2D坐标则能够避免深度的预测,只是我们初始化的BEV Queries实际上只有BEV的2D坐标,还缺乏车载坐标系的高度(z轴坐标),但高度的范围实际上要远远小于深度的范围。BEVFormer首先将每个Query提升成pillar-like Query,每个pillar对应4个不同的高度(通常在$[-5,3]$范围内取)。将高度与BEV坐标组合起来,就可以得到这个query对应的一组参考点,分别将他们投影到2D图像上。每个query可能投影到不止1个视角上,需要对该query对应的全部2D图像特征进行加权和以得到Spatial Cross-Attention的输出。
Temporal Self-Attention
Spatial Cross-Attention是为了让每个随机初始化的BEV Query能够与上一帧已经得到的BEV信息进行交互,从而得到相应的时序信息,辅助速度之类的属性预测。首先要根据惯导信息将时刻的BEV特征与当前时刻的BEV Queries $Q$对齐,得到$BEV’_{t-1}$。这是一个比较常见的操作,在之前FIERY论文与代码讲解的博客中也有相关的内容。然后也是使用一个deformable attention的操作进行时序上的交互,比较特别的部分是,这里是将$\{Q, BEV’_{t-1}\}$concate起来得到offset。

