BEVDepth论文解读
BEVDepth整体结构
BEVDepth认为深度估计对于基于相机的3D目标检测来说至关重要,因此尝试利用显式深度监督来解决这个问题。
BEVDepth实际上是在LSS的投影方法的基础上增加准确的深度估计模块和显式的深度监督。它指出了LSS的方案存在的3个问题:
- 不准确的深度
- 深度模块过拟合
- 不准确的BEV语义
BEVDepth的网络结构如图1所示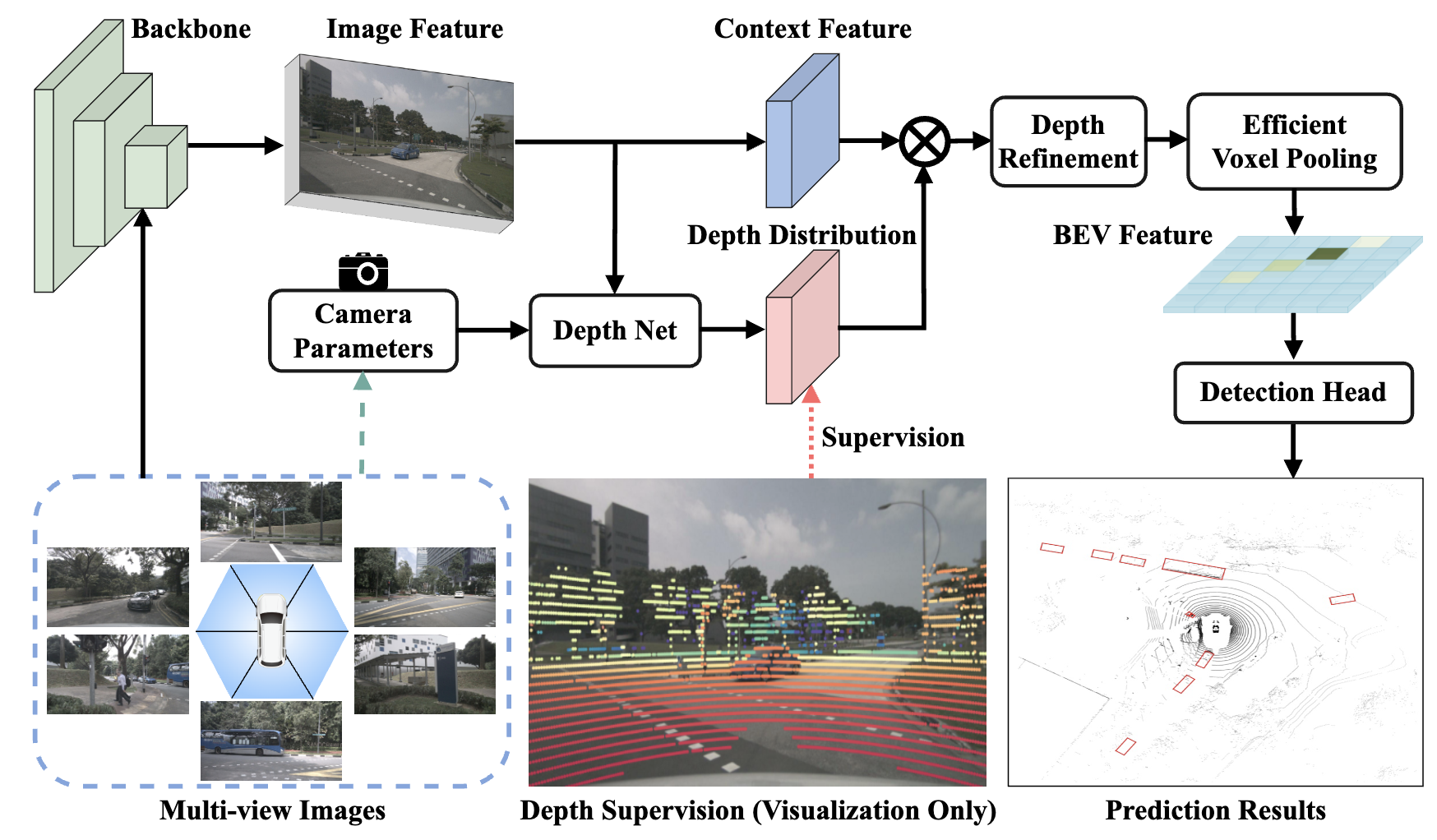
显式深度监督
以往的模型对于深度的监督几乎都只来自检测的损失,BEVDepth认为由于单目深度估计的困难,唯一的检测损失远远不足以监督深度模块。因此BEVDepth将LiDar点云投影到图像上来进行显式的监督。
这部分的原理并不难,但是代码实现上包含很多多传感器同步的细节,很多相关的博文并没有对此进行详细的介绍。BEVDepth主要是针对nuScenes数据集设计的,nuScenes中传感器采用的是硬同步方法。硬同步方法可以缓解查找时间戳造成的误差现象。该方法可以以激光雷达作为触发其它传感器的源头,当激光雷达转到某个角度时,才触发该角度的摄像头,这可以大大减少时间差的问题。这套时间同步方案可以做到硬件中,这样可以大大降低同步误差,提高数据对齐效果。nuScenes提供每张图像对应的时间戳,这个时间戳是根据惯导的频率进行同步。因此深度监督的数据生成包括以下几个部分
- 点云数据转到lidar时间戳对应的自车坐标系(实际上就是IMU坐标系)
- 点云数据从IMU坐标系转到global坐标系(nuScenes自己定义的一个global坐标系)
- 点云数据从global坐标系转到各相机时间戳对应的自车坐标系
- 点云数据从各相机时间戳对应的自车坐标系转到相机坐标系
- 结合图像上的裁剪操作,将点云数据从相机坐标系转到像素坐标系
由此,过滤到多余的点之后,就可以得到大致的像素对应的深度。由于nuScenes的LiDar是128线,实际上投影得到的监督比较稀疏,因此降采样之后实际上是针对的$16\times 44$特征图进行监督的。
Camera-aware 深度估计
BEVDepth认为将相机内参也作为输入信息,一同编码进行深度估计可以得到更好的深度估计结果。BEVDepth的DepthNet模块设计如下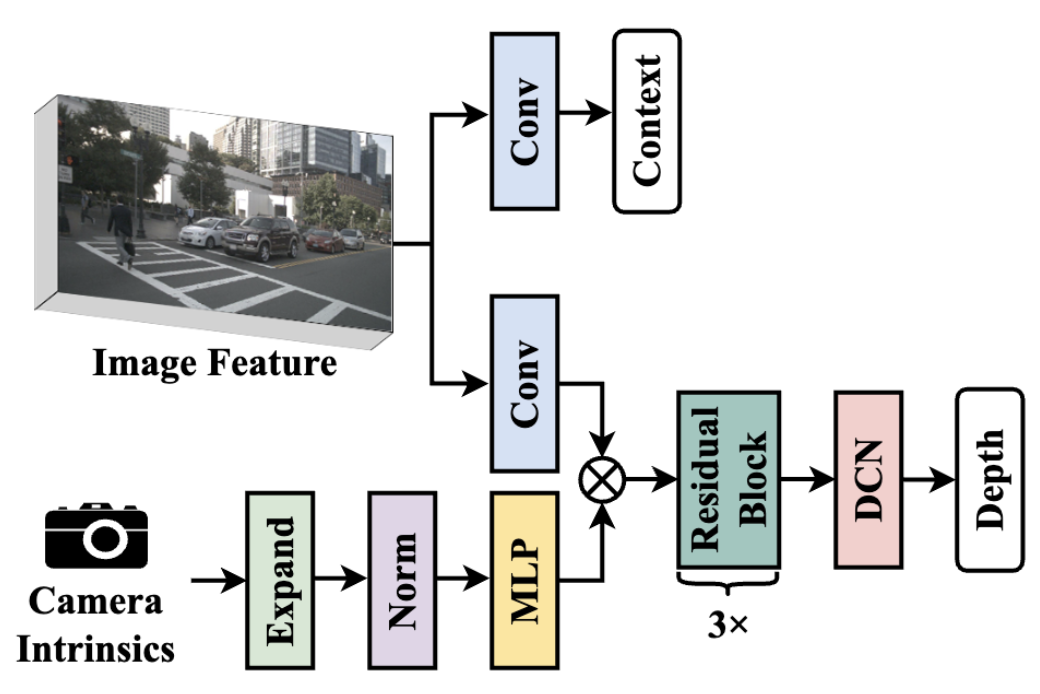
具体来说,先使用MLP讲相机内参的维度扩展到特征维度,然后使用类似SE模块的方式re-weight图像特征,最后把相机外参和相机内参concate起来辅助感知在自车坐标系下的位置。
深度细化模块
We first reshape $F^{3d}$ from $[C_F , C_D , H, W ]$ to $[C_F \times H, C_D , W]$, and stack several $3×3$ convolution layer on the $C_D × W$ plane. Its output is finally reshaped back and fed into the subsequent Voxel/Pillar Pooling operation.

