BEVDet论文解读
BEVDet整体结构
BEVDet是一个比较经典的在BEV视角下进行3D目标检测的范式,这种表示方式能够给下游的路径规划等任务带来极大的便利。BEVDet主要是重用现有的模块来构建其框架,但通过构建独占数据增强策略和升级非最大抑制策略,大大提高了其性能。此外,BEVDet的官方仓库跟进了很多包括深度估计、occupancy prediction在内的拓展版本,是初学者比较好的参考。
BEVDet的整体结构如图1所示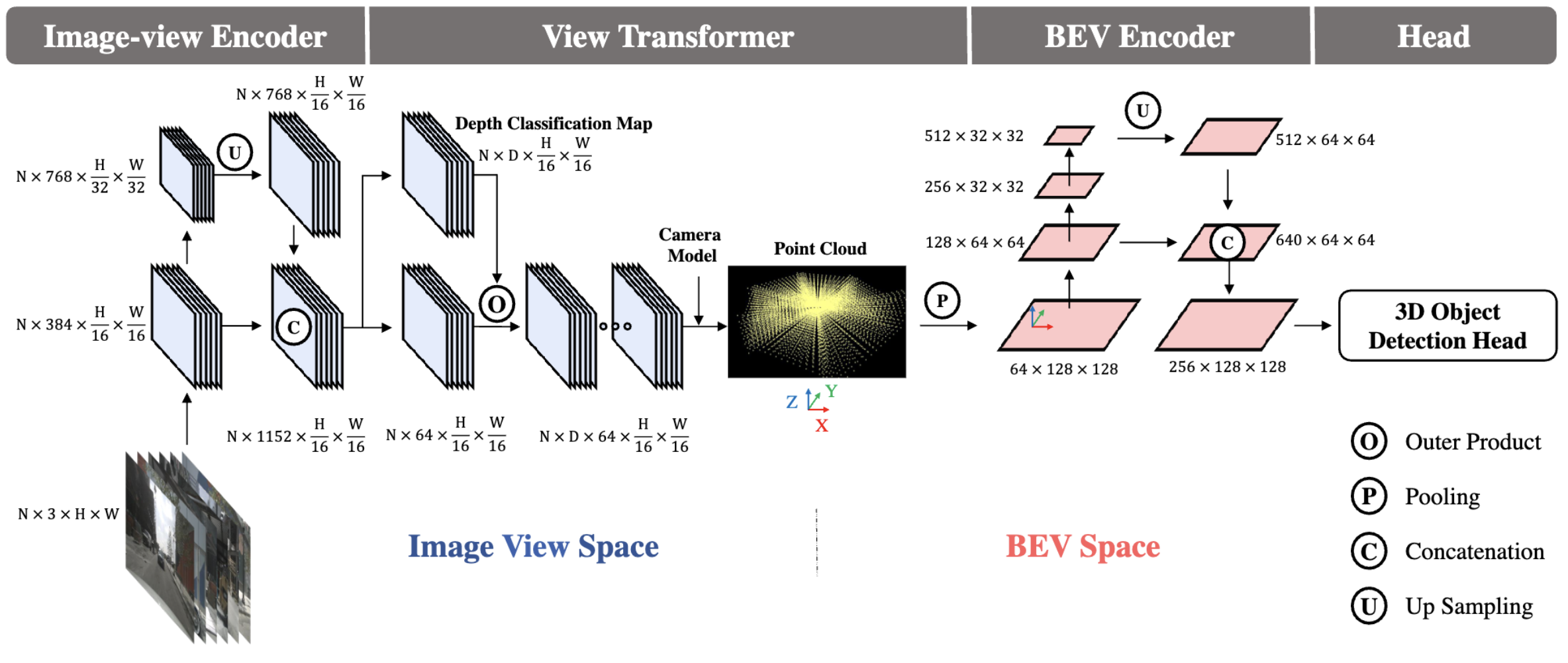
BEVDet由编码图像特征的image-view encoder,将特征从image-view转到BEV的view transformer,在BEV视角进一步编码特征的BEV encoder以及在BEV空间进行3D目标检测的特定任务头组成。遵循这一套范式,可以轻松的更换更适配自己应用场景的模块。
image-view encoder
To exploit the power of multi-resolution features, the imageview encoder includes a backbone for high-level feature extraction and a neck for multi-resolution feature fusion.
这个部分就是把输入的原始图像编码成特征,通常直接遵循2D检测的pipeline。为权衡精度和速度,常见的模块为ResNet/EfficientNet + FPN。
view transformer
这个部分直接使用LSS的视角转换方法,具体可参考FIERY与LSS详解。
BEV encoder
这个部分和image-view encoder比较类似,只是处理的特征变成了BEV视角的特征,仍然是用ResNet+FPN的方式。
head
3D目标检测任务需要检测目标的位置、尺寸、朝向以及包括行人、车辆、障碍物等移动目标的速度。BEVDet的head直接使用的是CenterPoint的head(以下简称为CenterHead)的第一阶段。
CenterHead也是一个比较经典的3D目标检测头,原文中对其描述如下
The first stage of CenterPoint predicts a class-specific heatmap, object size, a sub-voxel location refinement, rotation, and velocity. All outputs are dense predictions.
它解耦了3D目标框的不同属性,具体来说,主要包括以下几个sub head:
- Center heatmap head
- 由于中心点真值通常比较稀疏,真值的制作实际上对每个中心点渲染了高斯峰值以扩大面积
- Regression heads
- a sub-voxel location refinement
- height-above-ground
- 3D size
- yaw rotation angle
- 使用的是sin和cos值
在nusenes数据集中,目标的类别一共被分为了6个大类
tasks=[
dict(num_class=1, class_names=['car']),
dict(num_class=2, class_names=['truck', 'construction_vehicle']),
dict(num_class=2, class_names=['bus', 'trailer']),
dict(num_class=1, class_names=['barrier']),
dict(num_class=2, class_names=['motorcycle', 'bicycle']),
dict(num_class=2, class_names=['pedestrian', 'traffic_cone']),
]网络给每一个大类都分配了一个head,装在headlist中,而每个head内部都为预测的参数,包括(center_x,y,z、dim、rot、vel )分配了一个MLP,从而完成检测头的设计。所有的输出都使用L1 loss进行监督。(回归到对数大小了)
BEVDet的数据增强策略
BEVDet认为,训练阶段出现的过拟合问题可能是限制性能的主要因素。因此,BEVDet提出了数据增强策略来应对过拟合的问题。
应用于图像视图空间的增强策略不会改变 BEV 空间中特征的空间分布。但是过拟合的问题主要出现在BEV特征的学习方面。可以通过对BEV特征进行缩放、翻转、旋转等操作,这些操作在视图转换器的输出特征和3D对象检测目标上都需要进行,以保持它们的空间一致性。
BEVDet的改进NMS策略
. Scale-NMS scales the size of each object according to its category before performing the classical NMS algorithm.
这个部分提出了Scale-NMS。主要是针对3D目标检测中,不同类别的目标本身的尺寸不一致。比如行人,预测得到的TP可能和真值框的IoU为0。因此,BEVDet对不同类别的目标进行不同尺度的缩放,来做更符合客观场景的目标框过滤。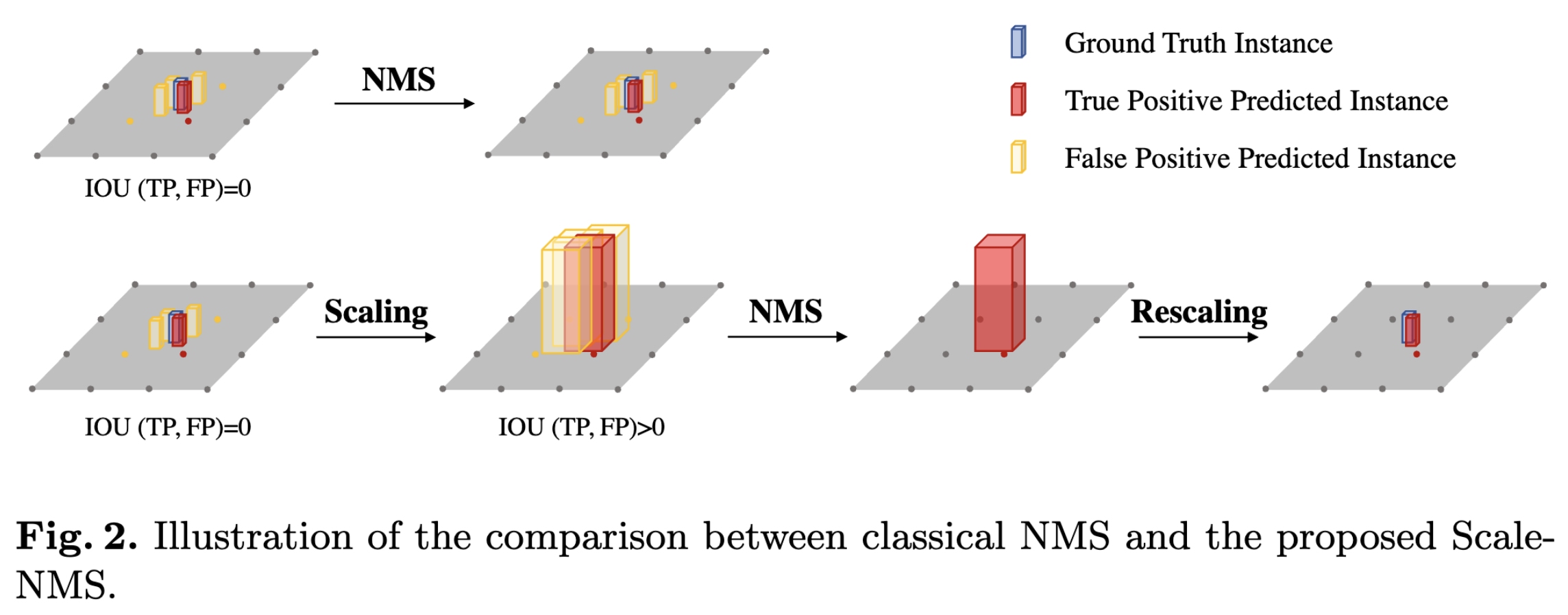
BEVPoolv2
基于LSS的方案在实际部署上还存在着很多问题,如推理速度慢和显存占用多。虽然BEVFusion已经提出过该方案的加速思路,但是收益仍然十分有限。BEVDet在其v2版本中提出了BEVPoolv2的思路,如下图所示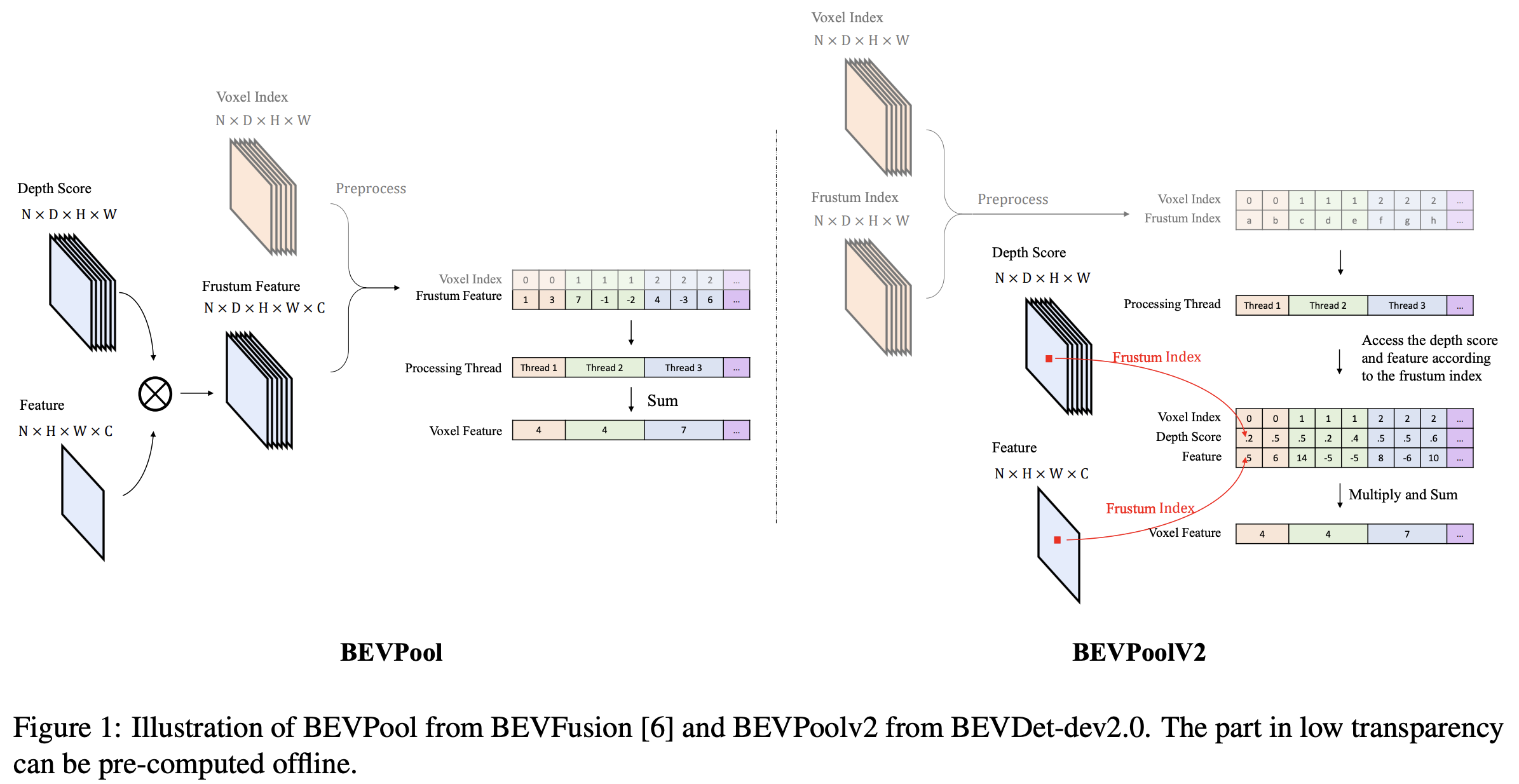
BEVDet的作者指出Lift的步骤需要计算、存储和预处理多个超大的视锥特征,因此针对这一点进行了优化。采用的方法就是offline的方式预计算depth_score和frustum的index,然后只在线进行多线程的相乘和累积,从而显著提高了FPS。
参考
BEVDet Paper
BEVDet Code
CenterPoint Paper
BEVPoolv2 Paper
https://zhuanlan.zhihu.com/p/586637783

