DETR原理与DETR3D原理
前情提要:之前的文章中,已经对注意力机制和原理Transformer的整体结构进行了介绍。本文将在其基础上介绍DETR原理和DETR3D原理。
DETR (ECCV 2020)
DETR总体思路是把目标检测看成一个set prediction的问题,使用Transformer来预测box的set。DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline,可以归结为:Backbone -> Transformer -> detect header。其结构图如下图所示
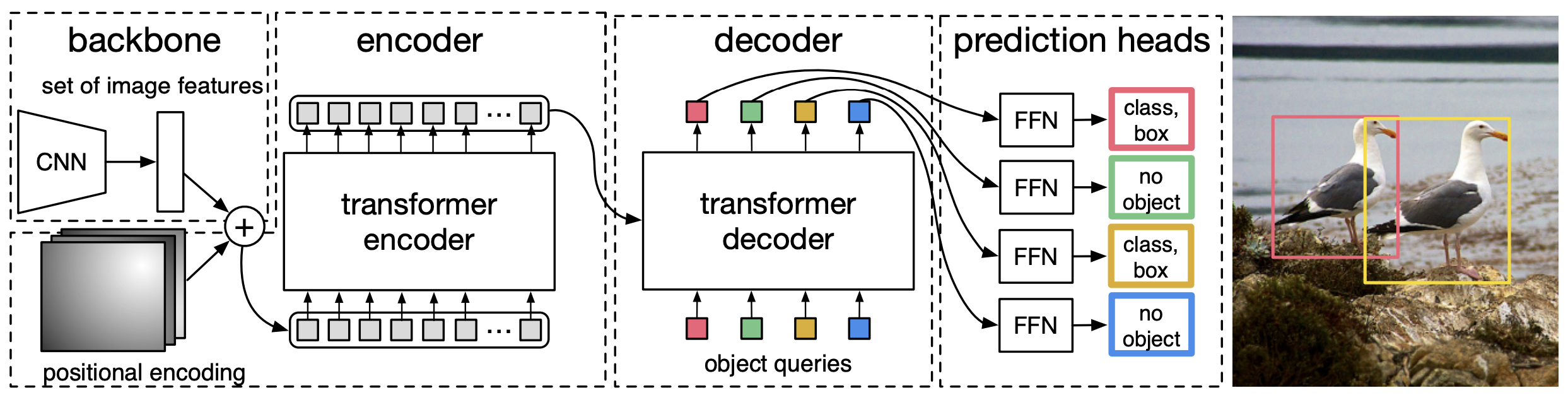
观察上图可以发现,DETR的整体结构与Transformer类似:Backbone得到的特征铺平,加上Position信息之后送到一堆Encoder里,得到一些candidates的特征。Candidates又被Decoder并行解码得到最后的检测框。
DETR Encoder
网络一开始是使用Backbone(比如ResNet)提取一些feature,然后降维到d×HW。
Feature降维之后与Spatial Positional Encoding相加,然后被送到Encoder里。
为了体现图像在x和y维度上的信息,作者的代码里分别计算了两个维度的Positional Encoding,然后Cat到一起。
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)FFN、LN等操作也与Transformer类似。Encoder最后得到的结果是对N个物体编码后的特征。
DETR Decoder
DETR Decoder的结构也与Transformer类似,区别在于Decoder并行解码N个object。每个Decoder有两个输入:一路是Object Query(或者是上一个Decoder的输出),另一路是Encoder的结果。Object Query是一组nn.Embedding的weight(就是一组学到的参数)。
与Transformer不同,DETR的Decoder也加了Positional Encoding。最后一个Decoder后面接了两个FFN,分别预测检测框及其类别。
Bipartite Matching
由于输出物体的顺序不一定与ground truth的序列相同,作者使用二元匹配将GT框与预测框进行匹配。这里可以参考之前写的匈牙利匹配的文章。
Loss Function
目标框的L1 loss和IoU loss。
DETR3D (CoRL 2021)
DETR3D是DETR范式在多目3D视觉任务上的拓展版本。对于多目3D视觉任务,就不得不提到当前仍占据主流的BEV感知方案。
BEV Perception
自动驾驶是3D目标检测重要的落地场景之一,通过纯视觉的方法,在2D图像上预测车辆、行人等3维BBox信息天然存在诸多困难,而2D的目标检测方法相对成熟,因此更多的3D目标检测方法更加关注如何从现有的2D检测框架迁移到3D任务中。从Tesla公布新的俯瞰视角(Bird’s-eys-view, BEV)目标检测的方法开始,越来越多的工作从俯视角出发做Detection, Segmentation。在BEV视角下做3D Detection,其好处如下:
- 基于视觉的检测属于前向视角,在成像的过程中天然存在近大远小的特点。例如车道线,在成像的图片上是一条相交的直线,而在俯视角下直接预测为直线更接近现实场景;同时在BEV视角做检测能更好避免截断问题
- 按照2D检测的pipeline,将2D中检测好的物体反投影回3D空间,需要预测深度、航向角等,引入了更多的误差
- LiDAR的点云数据天然支持BEV视角的检测、识别,更方便融合多模态的数据,以及与下游任务Prediction和Planning结合。
DETR3D结构
DETR3D将DETR中基于Transformer的2D检测框架引入到了3D检测任务中:一次性生成N个bbox,采用set-to-set损失函数计算预测和GT的二分图匹配损失。这种方式避免了常规3D检测任务中所需的深度估计模块,因此无需集中算力进行冗余信息的处理,而只关注在目标的特征之上,速度得到了较大的提升,也避免了重建带来的误差。此外,DETR3D也无需NMS等后处理操作。
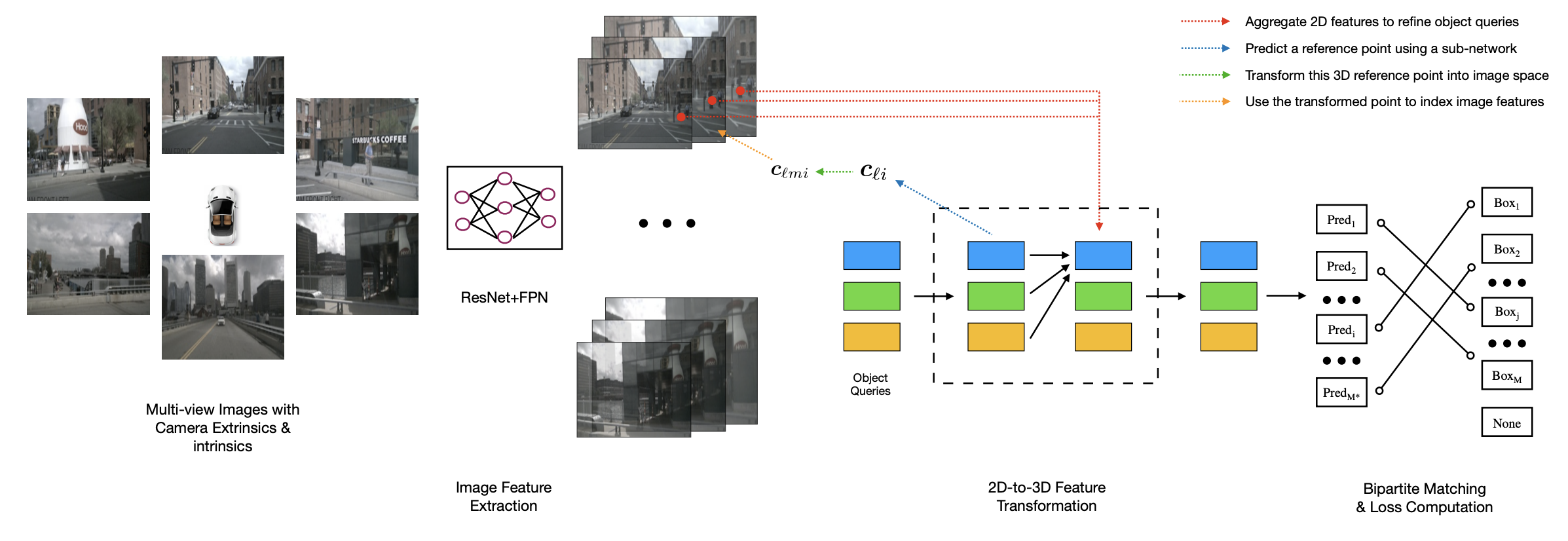
整个网络可大致分为四个部分:
Encoder
输入车载环视的6张图片,每张图片通过ResNet等2D骨干网络提取特征;再通过FPN得到4个不同尺度特征图Decoder
Decoder的输入是Encoder输出的特征图,在特征层面实现2D到3D的转换,避免深度估计带来的误差,同时这种set prediction的方式可以避免NMS等耗时的后处理操作。具体实现步骤如下object queries的生成类似DETR,先随机生成$M$个bounding box(类似先生成一堆anchor box,只不过这里的box是会被最后的loss梯度回传的)。
self.query_embedding = nn.Embedding(self.num_query, self.embed_dims * 2)如图中蓝线所示,使用子网络预测query在三维空间中的一个参考点(通常是简单的linear)。
self.reference_points = nn.Linear(self.embed_dims, 3)如图中绿线所示,利用相机内外参,将这个参考点反投影回图像中,找到其在原始图像中对应的位置。
- 如图中黄线所示,将投影后的Projection point 对应到FPN中的每一个尺度的feature map上。由于投影点经过下采样后在不同尺度的特征图上很可能没有刚好对应的特征点,因此采用双线性插值的方法来获取得到在每个尺度上的特征。然后将不同尺度上和不同位置相机上的提取到的特征进行求和平均处理
- 如图中红线所示,利用多头注意力机制,将找出的特征映射部分对queries进行refine。这种refine过程是逐层进行的,理论上,更靠后的layer应该会吸纳更多的特征信息。
- 如图中黑线所示,得到新的queries之后,再通过两个子网络(Linear+ReLU)分别预测bounding box和类别。
set-to-set loss
二分匹配
将真值set与预测值set进行匹配,利用匈牙利匹配实现一对一的对应。在匹配过程中,当在两个集合元素数量不相同时,通常使用将数量较少的一个集合补一堆空元素的方法来让集合元素数量相等。
在匹配的过程中,一个关键的步骤是衡量两个集合不同元素之间的相似度,论文中使用的是bounding box之间的相似度。bbox_cost = torch,cdist(bbox_pred, gt_bboxes, p=1)损失函数
损失函数部分保持和DETR一致,Decoder的每一层输出都计算loss。回归损失采用L1,分类损失使用focal loss。
参考
DETR Paper
DETR3D Paper
DETR3D Code
https://zhuanlan.zhihu.com/p/146065711
https://zhuanlan.zhihu.com/p/587380480
https://zhuanlan.zhihu.com/p/430198800

