Transformer详解
Transformer的提出
机器翻译领域主流的方案基于复杂的循环或卷积神经网络,其中包括编码器和解码器。以目前效果较好的RNN系列算法为例,这种架构存在并行度不够、计算效率低的问题。因为RNN要维护一个隐状态,该隐状态取决于上一时刻的隐状态。这种内在的串行计算特质阻碍了训练时的并行计算。特别是训练序列较长时,每一个句子占用的存储更多,batch size变小,并行度降低。有许多研究都在尝试解决这一问题,但是串行计算的本质无法改变。
在Transformer提出之前,已经有文章提出了基于注意力的架构。这种架构依然使用了编码器和解码器,只不过解码器的输入是编码器的状态的加权和,而不再是一个简单的中间状态。每一个输出对每一个输入的权重叫做注意力,注意力的大小取决于输出和输入的相关关系。这种架构优化了编码器和解码器之间的信息交流方式,在处理长文章时更加有效。但几乎所有的注意力机制都用在RNN上的。
既然注意力机制能够无视序列的先后顺序,捕捉序列间的关系,为什么不只用这种机制来构造一个适用于并行计算的模型呢?因此,作者提出了Transformer架构。这一架构规避了RNN的使用,完全使用注意力机制来捕捉输入输出序列之间的依赖关系。这种架构不仅训练得更快了,表现也更强了。
注意力机制
在熟悉Transformer的整体结构之前,先来看注意力机制的细节。
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. (Attention is all you need, 2017)
注意力机制可以理解成利用query去找对应的keys然后计算这些keys对应的value的加权和。由于query可能是比较模糊的描述,最通用的方法是把query和key各建模成一个向量。对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。
从本质上来说,注意力是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表信息的重要性,Value是对应的信息。
Scaled Dot-Product Attention
原论文称其提出的注意力机制为Scaled Dot-Product Attention,其结构如下
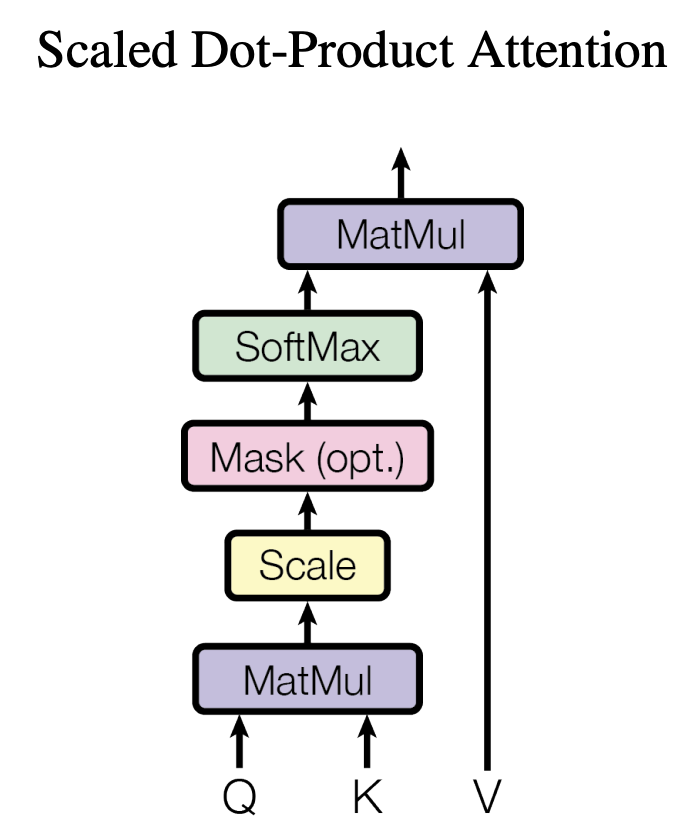
如图所示,注意力机制的核心过程就是通过Q和K计算得到注意力权重,然后再作用于V得到整个权重和输出。
对于输入Q、K和V来说,其输出向量的计算公式为:
此处$d_k$是query和key向量的长度,${\frac{1}{\sqrt{d_k}}}$就是上图中的scale,这一步是因为作者通过实验发现,softmax在绝对值较大的区域梯度较小,梯度下降的速度比较慢。较大的${d_k}$在完成${QK^T}$后会得到很大的值,这导致在经过sofrmax操作后产生非常小的梯度,不利于网络的训练。
注意力机制的计算过程从本质上来讲归纳为两个过程,第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。第一个过程可以继续细分为两个阶段:第一阶段根据Query和Key计算两者的相似性;第二阶段对第一阶段的原始分值进行归一化处理。
在第一个阶段,可以引入不同的函数和计算机制,根据Query和Key,计算两者的相似性或者相关性。算相似度并不只有求点乘这一种方式。另一种常用的注意力函数叫做加性注意力,它用一个单层神经网络来计算两个向量的相似度。相比之下,点积注意力在实践中要快得多,空间效率更高,因为它可以使用高度优化的矩阵乘法代码来实现。
在第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。
多头自注意力
在自注意力中,每一个单词的query, key, value应该只和该单词本身有关。因此,这三个向量都应该由单词的词嵌入得到。另外,每个单词的query, key, value不应该是人工指定的,而应该是可学习的。因此,我们可以用可学习的参数来描述从词嵌入到query, key, value的变换过程。综上,自注意力的输入
应该用下面这个公式计算:
其中,$E$是词嵌入矩阵,也就是每个单词的词嵌入的数组;$W^Q$、$W^K$、$W^V$是可学习的参数矩阵。在Transformer中,大部分中间向量的长度都用$d_{model}$表示,词嵌入的长度也是$d_{model}$。因此,设输入的句子长度为n,则$E$的size为$n \times d_{model}$,$W^Q$、$W^K$的size为$d_{model} \times d_k$,$W^V$的size为$d_{model} \times d_v$。
多头注意力允许模型共同关注不同位置的不同表示子空间的信息。仅使用单个注意力头的话,则会抑制这一点。多头注意力机制的结构图如下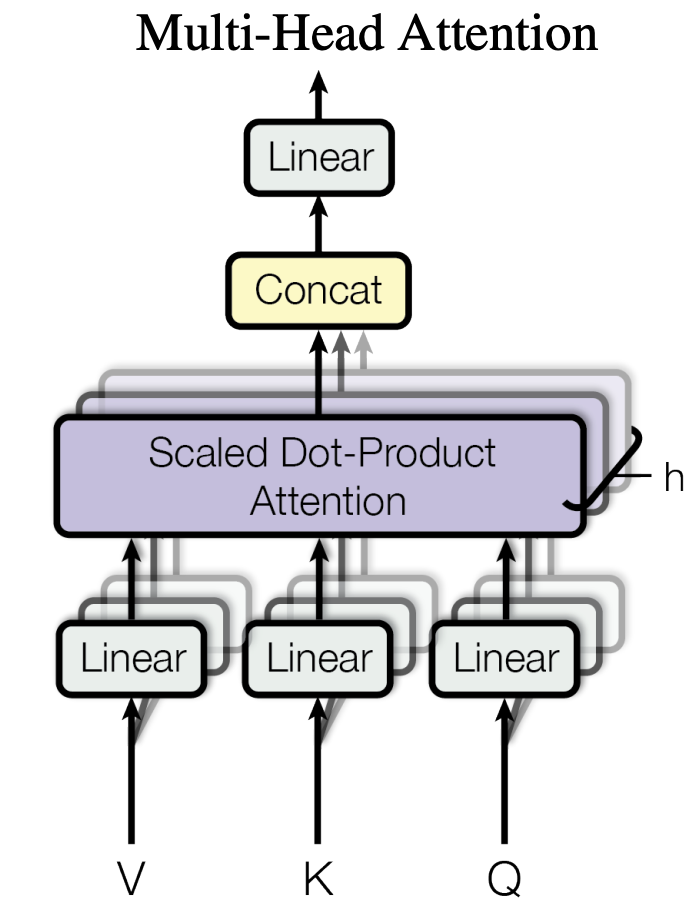
就像卷积层能够用多个卷积核生成多个通道的特征一样,我们也用多组$W^Q$、$W^K$、$W^V$生成多组自注意力结果。这样,每个单词的自注意力表示会更丰富一点。这种机制就叫做多头注意力,它是将原始的输入序列进行多组的自注意力处理过程,然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。以$h$表示多头注意力的“头数”,其计算公式为:
多头注意力机制其实就是将一个大的高维单头拆分成了h个多头,每个头可以关注输入的不同部分。因此能够表示比简单加权平均值更复杂的函数。由于每个头的维数降低,总计算成本与全维单头注意相似。
Transformer架构
Transformer 是基于 encoder-decoder 的架构,它使用注意力来编码,其整体结构如下图所示![]()
模型主干中,除了上文提到注意力模块,还有Add & Norm、Feed Forward,此外,decoder中的一个多头注意力前面加了Masked。
Add & Norm
Transformer使用了和ResNet类似的残差连接,即设模块本身的映射为$F(x)$,则模块输出为$Normalization(F(x)+x)$。和ResNet不同,Transformer使用的归一化方法是LayerNorm。Feed Forward
架构图中的前馈网络(Feed Forward)其实就是一个全连接网络。具体来说,这个子网络由两个线性层组成,中间用ReLU作为激活函数。
编码器
Transformer 的编码阶段概括如下:
- 为每个单词生成初始表达或 embeddings
- 对于每一个词,使用自注意力聚合来自所有其他上下文单词的信息,生成参考了整个上下文的每个单词的新表达
- 基于前面生成的表达,连续地构建新的表达对每个单词并行地重复多次这种处理。
Encoder 的 self-attention 中,所有 Key, Value 和 Query 都来自同一位置,即上一层 encoder 的输出。Decoder的设计类似,所有 Key, Value 和 Query 都来自同一位置,即上一层 decoder 的输出,不过只能看到上一层对应当前 query 位置之前的部分。生成 Query 时,不仅关注前一步的输出,还参考编码器的最后一层输出。
解码器
解码器的输入是当前已经生成的序列,该序列会经过一个掩码(masked)多头自注意力子层。我们先不管这个掩码是什么意思,暂且把它当成普通的多头自注意力层。它的作用和编码器中的一样,用于提取出更有意义的表示。
接下来,数据还会经过一个多头注意力层。这个层比较特别,它的K,V来自
,Q来自上一层的输出。为什么会有这样的设计呢?这种设计来自于早期的注意力模型。如下图所示,在早期的注意力模型中,每一个输出单词都会与每一个输入单词求一个注意力,以找到每一个输出单词最相关的某几个输入单词。用注意力公式来表达的话,Q就是输出单词,K, V就是输入单词。
这种并行计算有一个要注意的地方。在输出第$t+1$个单词时,模型不应该提前知道$t+1$时刻之后的信息。因此,应该只保留$t$时刻之前的信息,遮住后面的输入。这可以通过添加掩码实现。
这就是为什么解码器的多头自注意力层前面有一个masked。在论文中,mask是通过令注意力公式的softmax的输入为$-\infty$来实现的(softmax的输入为$-\infty$
,注意力权重就几乎为0,被遮住的输出也几乎全部为0)。每个mask都是一个上三角矩阵。
嵌入层
和其他大多数序列转换任务一样,Transformer主干结构的输入输出都是词嵌入序列。词嵌入,其实就是一个把one-hot向量转换成有意义的向量的转换矩阵。在Transformer中,解码器的嵌入层和输出线性层是共享权重的——输出线性层表示的线性变换是嵌入层的逆变换,其目的是把网络输出的嵌入再转换回one-hot向量。如果某任务的输入和输出是同一种语言,那么编码器的嵌入层和解码器的嵌入层也可以共享权重。
位置编码
现在,Transformer的结构图还剩一个模块没有读——位置编码。无论是RNN还是CNN,都能自然地利用到序列的先后顺序这一信息。然而,Transformer的主干网络并不能利用到序列顺序信息。因此,Transformer使用了一种叫做“位置编码”的机制,对编码器和解码器的嵌入输入做了一些修改,以向模型提供序列顺序信息。
细节重温
Transformer为何使用多头注意力机制?为什么不使用一个头
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
多头可以使模型共同关注不同位置的不同表示子空间的信息,这是单头注意力无法达到的效果,且矩阵的整体size不变,计算量和单个head差不多。
- 为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
- K和Q的点乘是为了得到一个attention score 矩阵。自身点乘可以表示在本空间内的相似度,但这个通常来说是不够的,泛化能力很差。为了使得模型有更强的表征能力,我们需要其在其他空间映射的相似度
- 直接拿K和K点乘的话,attention score 矩阵是一个对称矩阵。这种对称自反其实是不必要的
- 计算Attention为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
- 为什么在进行softmax之前需要对attention进行scaled(为什么除以$d_k$的平方根),并使用公式推导进行讲解
假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积$q\cdot k=\sum_{i=1}^{d_k}q_ik_i$将有均值为0,方差为$d_k$,因此使用$d_k$的平方根被用于缩放,因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样可以获得更平缓的softmax。当维度很大时,点积结果会很大,会导致softmax的梯度很小。为了减轻这个影响,对点积进行缩放。 - 在计算attention score的时候如何对padding做mask操作?
对需要mask的位置设为负无穷,再对attention score进行相加 - 为什么在进行多头注意力的时候需要对每个head进行降维?
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量 - Transformer的Encoder模块?
输入嵌入-加上位置编码-多个编码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层(包含激活函数层)) - 为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。 - 简单介绍一下Transformer的位置编码?有什么意义和优缺点?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。 - 还了解哪些关于位置编码的技术,各自的优缺点是什么?
相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
参考
Attention is all you need
https://zhouyifan.net/2022/11/12/20220925-Transformer/
https://www.ylkz.life/deeplearning/p10553832/
https://zhuanlan.zhihu.com/p/265108616
https://congchan.github.io/NLP-attention-03-self-attention/

![PAT - [1147] Heaps (30分)](/medias/featureimages/6.jpg)